
InfoWorld在分布式数据处理、流式数据分析、机器学习以及大规模数据分析领域精选出了2015年的开源工具获奖者,下面我们来简单介绍下这些获奖的技术工具。
1. Spark
在Apache的大数据项目中,Spark是最火的一个,特别是像IBM这样的重量级贡献者的深入参与,使得Spark的发展和进步速度飞快。
与Spark产生最甜蜜的火花点仍然是在机器学习领域。去年以来DataFrames API取代SchemaRDD API,类似于R和Pandas的发现,使数据访问比原始RDD接口更简单。
Spark的新发展中也有新的为建立可重复的机器学习的工作流程,可扩展和可优化的支持各种存储格式,更简单的接口来访问机器学习算法,改进的集群资源的监控和任务跟踪。
在Spark1.5的默认情况下,TungSten内存管理器通过微调在内存中的数据结构布局提供了更快速的处理能力。最后,新的spark-packages.org网站上有超过100个第三方贡献的链接库扩展,增加了许多有用的功能。
2. Storm
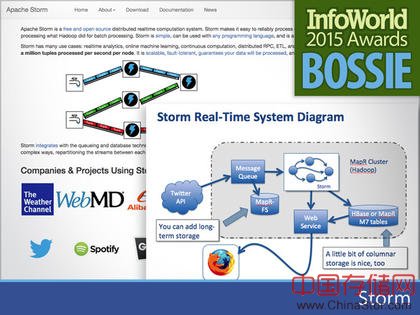
Storm是Apache项目中的一个分布式计算框架项目,主要应用于流式数据实时处理领域。他基于低延时交互模式理念,以应对复杂的事件处理需求。和Spark不同,Storm可以进行单点随机处理,而不仅仅是微批量任务,并且对内存的需求更低。在我的经验中,他对于流式数据处理更有优势,特别是当两个数据源之间的数据快速传输过程中,需要对数据进行快速处理的场景。
Spark掩盖了很多Storm的光芒,但其实Spark在很多流失数据处理的应用场景中并不适合。Storm经常和Apache Kafka一起配合使用。
3. Kylin
Apache Kylin由eBay研发并在2014年10月贡献给开源社区,于2014年11月加入Aapche孵化器项目,目前正在为毕业成Apache顶级项目投票中。整个开发团队都在eBay CCOE中国卓越中心,负责并主导Kylin产品的设计和研发。目前Kylin在eBay内部已经部署了非常大的应用平台,最大的单个Cube包含超过800亿条数据,系统中90%以上的查询响应小于5秒。这是eBay贡献至Apache软件基金会的第一个项目,也是第一个由中国开发团队完整开发并贡献至Apache软件基金会的第一个项目。目前Kylin社区已经发展了包括来自美团,明略数据等多位committer。
Apache Kylin(麒麟)由eBay公司开发,和大多数数据分析任务相类似,是一个通过ANSI-SQL解决超大OLAP数据立方体问题的应用程序。如果想象下eBay在过去和现在有多少在售商品的数量,以及eBay期望对这些物品相关的数据进行交叉分析,你就能够明白Kylin是为解决哪种类型的问题所设计的了。
和大部分其他数据分析应用一样,Kylin支持包括JDBC、ODBC,并为编程访问提供REST接口等多种访问方式。尽管Kylin还是Apache的孵化项目,并且社区也建立不久,但该项目具备相当的发展前景,开发团队渴望理解客户的使用案例,并对此做出积极的响应。运营并完善一个初创的数据立方体其实易如反掌,如果你在超大规模数据集的分析方面有需求的话,来关注Kylin吧!
4. H2O

H2O是一种分布式的内存处理引擎用于机器学习,它拥有一个令人印象深刻的数组的算法。早期版本仅仅支持R语言,3.0版本开始支持Python和Java语言,同时它也可以作为Spark在后端的执行引擎。
使用H2O的最佳方式是把它作为R环境的一个大内存扩展,R环境并不直接作用于大的数据集,而是通过扩展通讯协议例如REST API与H2O集群通讯,H2O来处理大量的数据工作。
几个有用的R扩展包,如ddply已经被打包,允许你在处理大规模数据集时,打破本地机器上内存容量的限制。你可以在EC2上运行H2O,或者Hadoop集群/YARN集群,或者Docker容器。用苏打水(Spark+ H2O)你可以访问在集群上并行的访问Spark RDDS,在数据帧被Spark处理后。再传递给一个H2O的机器学习算法。
5. Apex
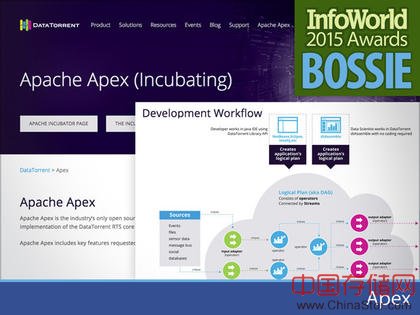
Apex是一个企业级的大数据动态处理平台,即能够支持即时的流式数据处理,也可以支持批量数据处理。它可以是一个YARN的原生程序,能够支持大规模、可扩展、支持容错方法的流式数据处理引擎。它原生的支持一般事件处理并保证数据一致性(精确一次处理、最少一次、最多一次)
以前DataTorrent公司开发的基于Apex的商业处理软件,其代码、文档及架构设计显示,Apex在支持DevOps方面能够把应用开发清楚的分离,用户代码通常不需要知道他在一个流媒体处理集群中运行。
Malhar是一个相关项目,提供超过300种常用的实现共同的业务逻辑的应用程序模板。Malhar的链接库可以显著的减少开发Apex应用程序的时间,并且提供了连接各种存储、文件系统、消息系统、数据库的连接器和驱动程序。并且可以进行扩展或定制,以满足个人业务的要求。所有的malhar组件都是Apache许可下使用。
6. Druid

Druid在今年二月转为了商业友好的Apache许可证,是一个基于“事件流的混合引擎,能够满足OLAP解决方案。最初他主要应用于广告市场的在线数据处理领域,德鲁伊可以让用户基于时间序列数据做任意和互动的分析。一些关键的功能包括低延迟事件处理,快速聚合,近似和精确的计算。
Druid的核心是一个使用专门的节点来处理每个部分的问题自定义的数据存储。实时分析基于实时管理(JVM)节点来处理,最终数据会存储在历史节点中负责老的数据。代理节点直接查询实时和历史节点,给用户一个完整的事件信息。测试表明50万事件数据能够在一秒内处理完成,并且每秒处理能力可以达到100万的峰值,Druid作为在线广告处理、网络流量和其他的活动流的理想实时处理平台。
7. Flink

Flink的核心是一个事件流数据流引擎。虽然表面上类似Spark,实际上Flink是采用不同的内存中处理方法的。首先,Flink从设计开始就作为一个流处理器。批处理只是一个具有开始和结束状态的流式处理的特殊情况,Flink提供了API来应对不同的应用场景,无论是API(批处理)和数据流API。MapReduce的世界的开发者们在面对DataSet处理API时应该有宾至如归的感觉,并且将应用程序移植到Flink非常容易。在许多方面,Flink和Spark一样,其的简洁性和一致性使他广受欢迎。像Spark一样,Flink是用Scala写的。
8. Elasticsearch
 8
8
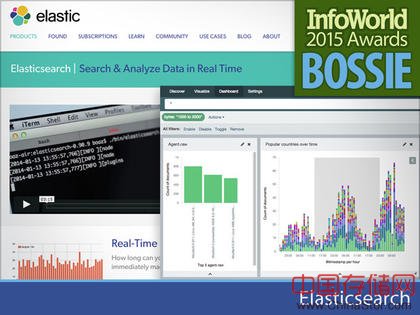
Elasticsearch是基于Apache Lucene搜索分布式文件服务器。它的核心,Elasticsearch基于JSON格式的近乎实时的构建了数据索引,能够实现快速全文检索功能。结合开源Kibana BI显示工具,您可以创建令人印象深刻的数据可视化界面。
Elasticsearch易于设置和扩展,他能够自动根据需要使用新的硬件来进行分片。他的查询语法和SQL不太一样,但它也是大家很熟悉的JSON。大多数用户不会在那个级别进行数据交互。开发人员可以使用原生JSON-over-HTTP接口或常用的几个开发语言进行交互,包括Ruby,Python,PHP,Perl,Java,JavaScript等。
9. SlamData
如果你正在寻找一个用户友好的工具,能理解最新流行的NoSQL数据的可视化工具,那么你应该看一看SlamData。SlamData允许您用熟悉的SQL语法来进行JSON数据的嵌套查询,不需要转换或语法改造。
该技术的主要特点之一是它的连接器。从MongoDB,HBase,Cassandra和Apache的Spark,SlamData同大多数业界标准的外部数据源可以方便的进行整合,并进行数据转换和分析数据。你可能会问:“我不会有更好的数据池或数据仓库工具吗?请认清这是在NoSQL领域。
10. Drill
Drill是一种用于大型数据集的交互分析的分布式系统,由谷歌的Dremel催生。Drill专为嵌套数据的低延迟分析设计,它有一个明确的设计目标,灵活的扩展到10000台服务器来处理查询记录数据,并支持兆级别的数据记录。
嵌套的数据可以从各种数据源获得的(如HDFS,HBase,Amazon S3,和Blobs)和多种格式(包括JSON,Avro,和buffers),你不需要在读取时指定一个模式(“读时模式”)。
Drill使用ANSI 2003 SQL的查询语言为基础,所以数据工程师是没有学习压力的,它允许你连接查询数据并跨多个数据源(例如,连接HBase表和在HDFS中的日志)。最后,Drill提供了基于ODBC和JDBC接口以和你所喜欢的BI工具对接。
11. HBASE

HBase在今年的里程碑达到1.X版本并持续改善。像其他的非关系型的分布式数据存储一样,HBase的查询结果反馈非常迅速,因此擅长的是经常用于后台搜索引擎,如易趣网,博科和雅虎等网站。作为一个稳定的、成熟的软件产品,HBase新鲜的功能并不是经常出现,但这种稳定性往往是企业最关心的。
最近的改进包括增加区域服务器改进高可用性,滚动升级支持,和YARN的兼容性提升。在他的特性更新方面包括扫描器更新,保证提高性能,使用HBase作为流媒体应用像Storm和Spark持久存储的能力。HBase也可以通过Phoenix项目来支持SQL查询,其SQL兼容性在稳步提高。Phoenix最近增加了一个Spark连接器,添加了自定义函数的功能。
12. Hive

随着Hive过去多年的发展,逐步成熟,今年发布了1.0正式版本,它用于基于SQL的数据仓库领域。目前基金会主要集中在提升性能、可扩展性和SQL兼容性。最新的1.2版本显著的提升了ACID语意兼容性、跨数据中心复制,以及以成本为基础的优化器。
Hive1.2也带来了改进的SQL的兼容性,使组织利用它更容易的把从现有的数据仓库通过ETL工具进行转移。在规划中讲主要改进:以内存缓存为核心的速度改进 LLAP,Spark的机器学习库的集成,提高SQL的前嵌套子查询、中间类型支持等。
13. CDAP

CDAP(Cask Data Access Platform)是一个在Hadoop之上运行的框架,抽象了建造和运行大数据应用的复杂性。CDAP围绕两个核心概念:数据和应用程序。CDAP数据集是数据的逻辑展现,无论底层存储层是什么样的;CDAP提供实时数据流处理能力。
应用程序使用CDAP服务来处理诸如分布式事务和服务发现等应用场景,避免程序开发者淹没在Hadoop的底层细节中。CDAP自带的数据摄取框架和一些预置的应用和一些通用的“包”,例如ETL和网站分析,支持测试,调试和安全等。和大多数原商业(闭源)项目开源一样,CDAP具有良好的文档,教程,和例子。
14. Ranger

安全一直是Hadoop的一个痛处。它不是说(像是经常报道)Hadoop是“不安全”或“不安全”。事实是,Hadoop有很多的安全功能,虽然这些安全功能都不太强大。我的意思是,每一个组件都有它自己的身份验证和授权实施,这与其他的平台没有集成。
2015年5月,Hortonworks收购XA /安全,随后经过了改名后,我们有了Ranger。Ranger使得许多Hadoop的关键部件处在一个保护伞下,它允许你设置一个“策略”,把你的Hadoop安全绑定到到您现有的ACL基于活动目录的身份验证和授权体系下。Ranger给你一个地方管理Hadoop的访问控制,通过一个漂亮的页面来做管理、审计、加密。
15. Mesos

Mesos提供了高效、跨分布式应用程序和框架的资源隔离和共享,支持Hadoop、 MPI、Hypertable、Spark等。
Mesos是Apache孵化器中的一个开源项目,使用ZooKeeper实现容错复制,使用Linux Containers来隔离任务,支持多种资源计划分配(内存和CPU)。提供Java、Python和C++ APIs来开发新的并行应用程序,提供基于Web的用户界面来提查看集群状态。
Mesos应用程序(框架)为群集资源协调两级调度机制,所以写一个Mesos应用程序对程序员来说感觉不像是熟悉的体验。虽然Mesos是新的项目,成长却很快。
16. NiFi

Apache NiFi 0.2.0 发布了,该项目目前还处于 Apache 基金会的孵化阶段。Apache NiFi 是一个易于使用、功能强大而且可靠的数据处理和分发系统。Apache NiFi 是为数据流设计。它支持高度可配置的指示图的数据路由、转换和系统中介逻辑。
Apache NiFi是由美国过国家安全局(NSA)贡献给Apache基金会的开源项目,其设计目标是自动化系统间的数据流。基于其工作流式的编程理念,NiFi非常易于使用,强大,可靠及高可配置。两个最重要的特性是其强大的用户界面及良好的数据回溯工具。
NiFi的用户界面允许用户在浏览器中直观的理解并与数据流举行交互,更快速和安全的进行迭代。
其数据回溯特性允许用户查看一个对象如何在系统间流转,回放以及可视化关键步骤之前之后发生的情况,包括大量复杂的图式转换,fork,join及其他操作等。
另外,NiFi使用基于组件的扩展模型以为复杂的数据流快速增加功能,开箱即用的组件中处理文件系统的包括FTP,SFTP及HTTP等,同样也支持HDFS。
NiFi获得来来自业界的一致好评,包括Hortonworks CEO,Leverage CTO及Prescient Edge首席系统架构师等。
17. Kafka
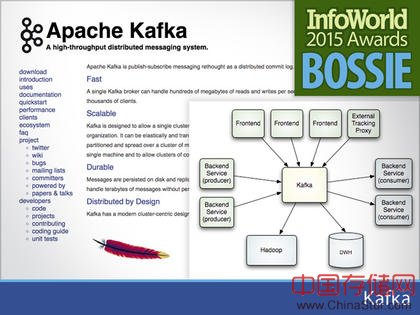
在大数据领域,Kafka已经成为分布式发布订阅消息的事实标准。它的设计允许代理支持成千上万的客户在信息吞吐量告诉处理时,同时通过分布式提交日志保持耐久性。Kafka是通过在HDFS系统上保存单个日志文件,由于HDFS是一个分布式的存储系统,使数据的冗余拷贝,因此Kafka自身也是受到良好保护的。
当消费者想读消息时,Kafka在中央日志中查找其偏移量并发送它们。因为消息没有被立即删除,增加消费者或重发历史信息不产生额外消耗。Kafka已经为能够每秒发送2百万个消息。尽管Kafka的版本号是sub-1.0,但是其实Kafka是一个成熟、稳定的产品,使用在一些世界上最大的集群中。
18.OpenTSDB

opentsdb是建立在时间序列基础上的HBase数据库。它是专为分析从应用程序,移动设备,网络设备,和其他硬件设备收集的数据。它自定义HBase架构用于存储时间序列数据,被设计为支持快速聚合和最小的存储空间需求。
通过使用HBase作为底层存储层,opentsdb很好的支持分布与系统可靠性的特点。用户不与HBase的直接互动;而数据写入系统是通过时间序列的守护进程(TSD)来管理,它可以方便的扩展用于需要高速处理数据量的应用场景。有一些预制连接器将数据发布到opentsdb,并且支持从Ruby,Python以及其他语言的客户端读取数据。opentsdb并不擅长交互式图形处理,但可以和第三方工具集成。如果你已经在使用HBase和想要一个简单的方法来存储事件数据,opentsdb也许正好适合你。
19. Jupyter

大家最喜欢的笔记应用程序都走了。jupyter是“IPython”剥离出来成为一个独立的软件包的语言无关的部分。虽然jupyter本身是用Python写的,该系统是模块化的。现在你可以有一个和iPython一样的界面,在笔记本电脑中方便共享代码,使得文档和数据可视化。
至少已经支持50个语言的内核,包括Lisp,R,F #,Perl,Ruby,Scala等。事实上即使IPython本身也只是一个jupyter Python模块。通过REPL(读,评价,打印循环)语言内核通信是通过协议,类似于nrepl或Slime。很高兴看到这样一个有用的软件,得到了显著的非营利组织资助,以进一步发展,如并行执行和多用户笔记本应用。
20. Zeppelin

Zeppelin是一个Apache的孵化项目. 一个基于web的笔记本,支持交互式数据分析。你可以用SQL、Scala等做出数据驱动的、交互、协作的文档。(类似于ipython notebook,可以直接在浏览器中写代码、笔记并共享)。
一些基本的图表已经包含在Zeppelin中。可视化并不只限于SparkSQL查询,后端的任何语言的输出都可以被识别并可视化。 Zeppelin 提供了一个 URL 用来仅仅展示结果,那个页面不包括 Zeppelin 的菜单和按钮。这样,你可以轻易地将其作为一个iframe集成到你的网站。
Zeppelin还不成熟。我想把一个演示,但找不到一个简单的方法来禁用“Shell”作为一个执行选项(在其他事情)。然而,它已经看起来的视觉效果比IPython笔记本应用更好,Apache Zeppelin (孵化中) 是 Apache2 许可软件。提供100%的开源。
原文链接: Bossie Awards 2015: The best open source big data tools
译者简介:张晓东, 引跑科技副总裁,关注云计算领域。