今年4月份,CSDN曾采访过来自UC Berkeley计算机系AMPLab的博士生辛湜(英文名Reynold Xin),他是Shark的作者,同时也是Spark的核心成员(@hashjoin),如今他又多了一个新的身份——Databricks的联合创始人。Databricks可谓阵容豪华,包括了UC Berkeley计算机教授、AMPLab联合创始人Ion Stoica,UC Berkeley计算机科学教授Scott Shenker(Scott计算机历史上论文被引用次数最高的人,同时也是知名SDN公司Nicira的联合创始人及前CEO),Spark原作者、MIT教授Matei Zaharia。近期,来自Andreessen Horowitz的1400万美元投资,以及Cloudera在2013 Strata+Hadoop大会抛出的重磅消息,使Databricks再次引起了业界关注。CSDN再次采访了辛湜,向他了解了关于Spark以及Databricks的最新消息。
以下为专访整理:
CSDN:目前Spark的发展状况是怎么样的?未来的研究方向是什么?
辛湜:UC Berkeley AMPLab今年把Spark贡献给了ASF(Apache Software Foundation)开源社区,Spark已经成为一个ASF项目,正式名字是Apache Spark。很多公司和机构开始利用Spark分析和提取数据,编写机器学习和图的应用等等。在中国我知道淘宝、腾讯、优酷、大众点评等互联网公司都有成功的案例。全球各地已经有接近100个开源贡献者,包括了很多身在中国的工程师。除了Hadoop MapReduce之外,Spark是用户数和贡献人数最多的大数据开源系统。Spark可能会在不久的将来超越MapReduce。
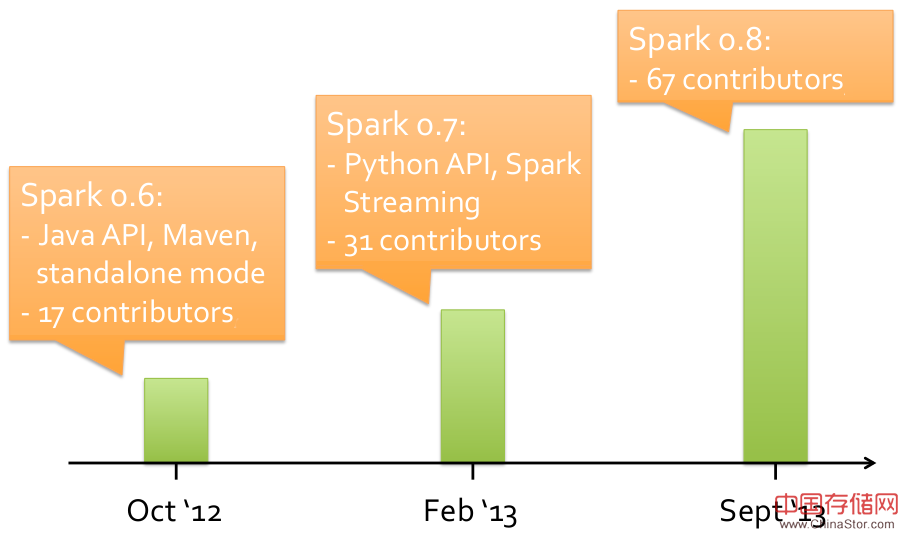
2012年10月-2013年9月Spark贡献者的增长状况
作为一个ASF的项目,Spark的发展很大程度上是开源社区共同决定的。UC Berkeley和Databricks的团队希望未来Spark的发展重点在以下几个方面:
- Spark Streaming:大大提高Spark流处理的能力和稳定性,使用户可以用同一套代码进行大数据流处理和批量处理。
- MLLib:Spark 0.8里面增加的一个高质量的机器学习库。我们希望添加更多的算法到这个库里面,使得Spark成为分布式机器学习应用的标准。
- GraphX:现在有越来越多的社交网络分析以及机器学习算法可以利用图算法来实现,GraphX是在Spark之上实现的一个图框架,可以让用户凭借短短几行代码简洁地实现多种图算法。
- 易用性:简化安装、设置以及使用。完善Python/Java的API。我们也在考虑提供其他语言的API,包括R等等。
- 稳定性:和用户以及开源社区合作,提高稳定性,部署更多的应用在Spark上。
- 性能:Spark虽然在这方面上起点比较高,但是还有很大的提升空间。
CSDN:能否介绍下Databricks的情况,您在Databricks主要的工作是什么?创业会对您的研究工作产生什么影响?

辛湜:今年年中,我和几个AMPLab的同僚(包括Ion Stoica教授和Spark的原作者Matei Zaharia)共同创立了Databricks公司。Databricks的目标是从Spark开始,构建一系列更强大、更简单的大数据分析处理工具和平台。九月份的时候,我们正式宣布从硅谷风投Andreessen Horowitz获得A轮融资1400万美元,利用这些资金吸引人才,提高大数据生态系统发展的步伐。
因为是创业公司的关系,我现在做的事情很多。一天中可能一部分时间在负责招聘,一部分时间探讨公司决策,一部分时间在给公司员工买零食,然后剩下的大量时间用来写代码和code review。长远来看,我希望把主要的时间放在产品研发上。

Databricks团队成员
后排从左向右依次为:Andy(Spark Summit的组织者)、Arsalan(曾在麦肯锡主管大数据以及IT策略管理咨询,现已加入Databricks)、Matei Zaharia、Ion Stoica、Scott Shenker、Mike Franklin(AMPLab director)
前排从左向右依次为:Ali( 世界知名的分布式系统、分布式算法以及调度系统专家)、辛湜、Patrick(Sparrow的作者之一,也是Spark其中一个最重要的贡献者)、Aaron(Databricks工程师)
CSDN:在刚结束的2013 Strata+Hadoop大会上,Cloudera宣布联合Databricks提供Spark企业级服务,这对于Databricks和Spark都有何重大意义?
辛湜:尽管Spark现在有很多互联网以及科技公司的成功案例,得到了技术人员和开源社区的肯定,但是这个项目最终的成功需要大量企业级的应用。这个合作关系有三重意义:第一,它验证了整个大数据生态圈对Spark发展的认同,越来越多的机构认识到Spark可以帮助他们更高效、更快地从大数据中获取有价值的信息以辅助商业决策。第二,这个合作关系为用户提供企业级的支持奠定了基础。第三,Spark从项目初始阶段就是以尽最大程度兼容Hadoop而设计的(可以直接读取Hadoop文件以及Hadoop兼容的储存系统),两个公司的合作可以确保以后Spark成为Hadoop生态系统中最重要的框架之一,为Spark和Hadoop用户带来更大的价值。
CSDN:自YARN之后,Hadoop可以运行更多的处理集群,对比其它的数据处理框架,Spark的优势会体现在什么地方?杀手级应用场景是什么?
辛湜:短期来看,最大的应用是进行复杂的数据分析,比如说利用机器学习或者图算法来实现推荐系统等等。长远来看,Spark的强项是可以用同一个框架来满足很多不同的应用场景,包括ETL、SQL、机器学习、图分析等等,更好的把这些应用场景集成起来。
打个比方,在2007年iPhone出来之前,很多人会携带手机打电话和发短信,数码相机用于拍照,mp3/iPod来播放音乐,还有GPS导航装置。2007年之后,随着iPhone和其他智能手机的发展,以上大多数功能都被智能手机取代了。虽然智能手机在每个应用上的性能不一定能赶超专业设备,但是因为其简单小巧,大多数人更倾向于直接使用智能手机。除此之外,将这些功能集成到一部小巧的智能手机上也诞生了新的应用,比如说用户可以拍一张照片,直接利用手机内置的GPS给照片标上地理位置,上传到微博上和朋友分享,这些应用是单一的专业设备无法满足的。我们希望Spark会成为大数据时代的智能手机。