合理的灾难恢复计划对于依赖软件为其运营提供动力的企业至关重要。

从本地到云的外流并没有改变这一点。如果您严重依赖 SaaS 应用程序(如 Atlassian Jira、Jira Service Management 或 Confluence)来交付产品和服务,则必须在灾难恢复计划中包括恢复存储在这些服务中的关键数据的特定步骤。在本文中,我们将引导您完成为 SaaS 应用程序创建灾难恢复计划的核心构建基块。
为什么 SaaS 数据需要灾难恢复计划?
我们每天至少从同行那里得到一次这样的问题:“为什么我需要云的灾难恢复计划,特别是 SaaS?
原因如下:当企业开发自己的软件时,他们可以控制数据隐私、安全性和可靠性。云应用程序承担了托管自己的解决方案的大部分责任,但不是全部责任。
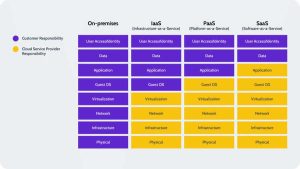
它被称为责任共担模型。它通常与 AWS 相关联,但共同责任的概念支配着所有云计算,包括 Atlassian。从本质上讲,您和 cloud 提供商共同承担保护数据的责任。SaaS公司将保证除用户访问和数据之外的一切。你有责任保护这些东西。
虽然某些 SaaS 产品提供备份和还原功能,但它们可能缺乏细粒度的恢复控制、通过详细审核日志实现的全面数据可见性或数据安全保证。因此,为您依赖的每个 SaaS 产品制定灾难恢复计划至关重要。
步骤 1:定义 RTO 和 RPO 应推动恢复策略的两个关键指标是 RPO
(确定数据丢失容限)和 RTO(为最大程度地减少停机时间设定基准)。
RPO 指标围绕一个基本问题:“您能承受损失多少数据?以下是我们经常构建事物的方式:如果您每 24 小时在午夜备份一次数据,并在晚上 11:59 发生灾难,您将丢失一整天的数据。
这种风险水平对某些企业来说是可以容忍的,但对其他企业来说是不可接受的。定义数据丢失的风险承受能力将指导您的技术决策有效地满足这些要求。
若要确定 RPO,需要考虑数据的关键性以及潜在数据丢失对组织的影响。不同的服务或应用程序可能具有不同的 RPO 阈值。例如,任务关键型系统可能需要零或接近零数据丢失的实时复制,而非关键系统可能容忍更长的备份间隔。
RTO 指标侧重于从灾难中恢复和恢复正常操作的速度。想象一下陨石撞击数据中心的场景。让您的系统恢复运行需要多长时间?这涉及采购备用基础结构或从备份还原等因素。恢复所需的时间因所讨论的服务而异。
某些服务可以实现快速恢复时间(可能在几分钟内),而其他服务可能需要更长的时间,也许需要一整天或更长时间。了解每个服务或应用程序的独特恢复时间表对于有效的灾难恢复规划至关重要。
入门的关键方法是与组织中的利益干系人接洽,以确保他们支持并就定义的 RPO 和 RTO 目标达成一致。这种合作将促进对灾难的潜在影响和所需的恢复时间表的共同理解。
步骤 2:选择恢复策略 选择正确的策略
归结为稳健性与成本的权衡。下面是来自 AWS 的图表,该图形也适用于 Atlassian 提供的产品,有助于说明选择范围。
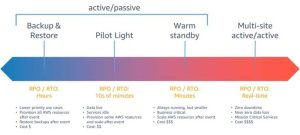
来源:云中的灾难恢复选项 – AWS 上的工作负载灾难恢复:云中的恢复
让我们从左侧的备份和还原解决方案开始。这是最简单,最实惠的选择。但是,这里的恢复时间可能需要数小时甚至更长时间。实质上,您正在将最新备份还原到灾难恢复位置。
继续前进,我们有指示灯选项。使用此方法,可以在降低的容量中运行一些基本服务。大多数服务正在运行,但已缩减到“缩放到零”级别。代码或应用程序更新将推送到 DR 位置,就像更新主位置一样。
接下来是备用策略。在这里,一切都已启动并运行,尽管与主环境相比容量较小。它类似于 Pilot Light 选项,但所有服务都至少以一定的容量运行——没有扩展到零。
最后,我们有主动/主动解决方案。这是一种在 2 个并行流中运行完整服务的方法,允许您近乎实时地在它们之间切换。但是,值得注意的是,此选项的成本增加了一倍,使许多公司不太可行。
您选择的恢复策略取决于您的风险承受能力以及您愿意投资多少来降低风险。根据您的行业,您将拥有构成运营基础的核心系统以及外围系统。虽然核心系统一整天的停机时间对大多数企业来说可能是痛苦的,但如果它是运行营销计划、收集统计数据或其他辅助服务的工具,则影响可能不那么重要。
这意味着您需要为组织内的各种系统制定不同的 DR 计划。虽然服务 DR 计划之间可能存在重叠元素,但由于 RPO 和 RTO 的潜在变化,请务必考虑每个服务的计划。
第 3 步:测试 DR 计划 为了有效地测试您的灾难恢复计划
这里有一个有用的清单,可帮助您集中精力,组织灾难恢复计划的桌面测试:
桌面测试是将所有想法和方法摆在每个人面前的好方法。它允许所有利益相关者对您应该如何进行灾难恢复工作有发言权。 演练任何可能阻碍甚至阻止 DR 计划完全有效的内部和外部依赖项。在实施计划之前,解决和解决这些依赖项至关重要。 他的会议构成了我们灾难恢复计划的基础,因此我们必须彻底记录所有内容。最好让参与者签署文档,以避免以后出现任何混淆。 创建责任列表:
这确定了如果灾难中断您的业务,谁随时待命;负责执行灾难恢复计划不同阶段的人员。该列表应清楚地概述和更新,以便新团队成员知道谁将在紧急情况下做什么。 为不同类型的灾难制定计划:
虽然您无法为每一种可能的灾难做好计划,但评估您面临的风险并确定其优先级非常重要。无论是恶意软件攻击、数据中心中断还是第三方提供商中断,请选择要准备的中断。 了解停机和数据丢失的成本:
当 SaaS 工具对流程和工作流至关重要时,中断可能会耗尽生产力和现金。Atlassian 在 14 年 2022 月的 50 天中断就是这样一个例子,最终影响了超过 50000名用户。停机导致撤销对关键 SaaS 产品(如 Jira、Confluence 和 Opsgenie)的访问权限。它还导致数据丢失。根据 Atlassian 自己的计算,客户停机的平均成本为5600 美元,但实际成本确实因企业而异。《在线灾备计算器》
当然,为此类活动做准备会产生多个层面的成本,因此请务必仔细考虑您要投资哪些故障保险以及投资到什么程度。一个好的起点是备份和恢复软件,即使应用程序的某些部分无法正常运行,也能保持关键操作。
回顾:一目了然,测试 DR 计划的清单应如下所示:
- 了解为什么需要 SaaS 灾难恢复计划。
- 设置 RPO 和 RTO。
- 与相关利益干系人确认要保护的业务功能。
- 确定执行灾难恢复计划所需的内部和外部工具,同时考虑到 SaaS 数据的安全性和隐私性。
- 创建清晰且相关的责任清单,说明谁在什么情况下随叫随到。
- 确定您正在规划的灾难类型,因为您无法计划所有内容。
- 记录计划,使其易于访问,并让适当的利益相关者签署。
关于Jodocus公司
作为 Atlassian 白金解决方案合作伙伴,是使用 Atlassian 软件优化业务流程的专家,提供流程管理、工作流程优化、数字化