该篇文章系SDN实战团微信群组织的线上技术分享整理而成,本次由上海交通大学在读博士生张鹏飞给我们带来关于SDN测量的研究尝试的分享。
嘉宾介绍
--------------------------------------------------------------------------


张鹏飞,上海交通大学博士在读,来自OMNILab。主要研究方向:云计算环境的网络测量及优化。2011年起接触OpenStack,2013-2014年于思科硅谷OpenStack Research Team实习一年,期间工作在2014 OpenStack Summit上进行了展示。
--------------------------------------------------------------------------
【分享正文】各位前辈,大神好!我是张鹏飞,现在上海交大博士生在读,来自OMNILab。我的主要研究兴趣是SDN 网络测量和分析,今天厚着脸皮分享下我们在SDN测量方面的一些工作,希望能够得到大家的反馈意见,最好是批评。因为和业界接触没有那么多,如果分享的Idea有不切实际的地方,恳请大家指出来,谢谢!
网络测量方面,其实无论是SDN还是传统网络,都有很多成熟的工作和Solution,我们分享的工作的出发点,是探索在纯OpenFlow的条件下能否实现网络承载应用的性能测量,所以第一个关键词是SDN,第二个关键词是业务性能。我这里先整理了一些传统的网络测量方法和工具,基本可以用下面的图做一个分类:
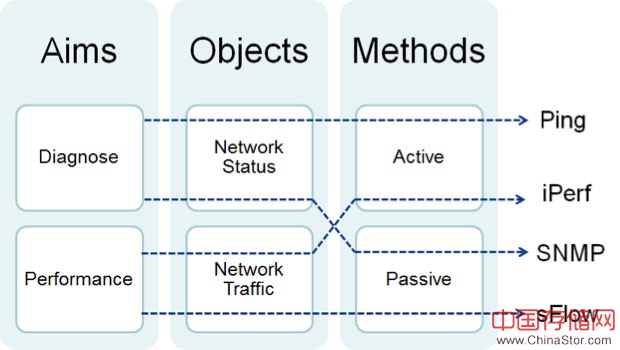
测量目标:诊断、性能
测量对象:网络状态、网络流量(报文)
测量方法:被动、主动
比如Ping大致可以看成是以诊断为目标,网络状态为对象的主动测量,etc。当然这个图里没有放进所有的已有测量方法,只是一个大致的分类。而且容易理解,全连接的话其实是2*2*2=8条路线,图中不方便都画出来,只是举了几个例子。
在SDN里,特别是OpenFlow里,已经默认有的网络测量的信息包括:网络拓扑,链路状态等,而如果需要测量不同应用的网络流量和网络性能,则需要额外的努力。当然,很多厂商在网络测量方面已经有成熟的解决方案,我们这里的思路主要是探索在只用OpenFlow基本协议的情况下有没有可能对网络中业务的时延、丢包等性能进行测量。
这里我们有两个工作在进行,一个是用于诊断的“Netography”,另一个是主要关注应用的网络流量和性能的“ScoutFlow”,其中前者会在NOMS2016上展示,后者正在进行。这两个工作如果放在前面的Roadmap中,大约是下面这样的:

先讲下Netography这个诊断测量的工作。Netography这个工作主要是我们Lab的宇粟同学完成的,如果有细节上的问题也可以找他聊。
其实之前有很多的研究集中在了流表项配置冲突或者是链路故障的分析了,我们这个工作考虑的是测量流表实际执行中结果,即报文过某个交换机的前后的实际变化以及其中所匹配的流表项。方法是主动测量,发送带有特定tag的探针报文,交换机上多配置一个流表,用于处理探针包,使得探针报文能够在正常转发的同时复制一份返回给我们的收集器。通过逐跳比较探针报文,达到诊断的目的。基本上可以说是SDN中的Traceroute。大致的诊断流程可以看下图:
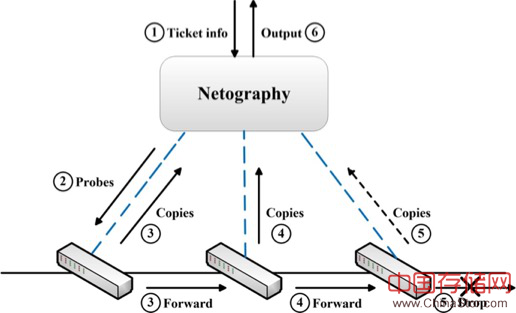
具体的交换机流表配置细节这里就不赘述了,有兴趣的回头我们可以提供发表的原文,大致思路是利用多流表,把带有特定tag(比如VLAN,当然使用了VLAN的网络可以用其他的比如MPLS)的探针包copy一份出来转发,同时需要在正常转发的流表中加上一个Action,把match的ruleID写到包头对应的标志位上。
这样的traceroute,主要可以用于解决下面的诊断问题:
1. 可达性,能够知道报文在哪一跳之后出了问题
2. 拥塞:通过两个报文之间的时间间隔可以大致知晓链路拥塞情况
3. 流表冲突:可以看到实际匹配的是哪个流表项,用于诊断流表规则的问题
另外一个工作ScoutFlow,现在我们还在做,这里分享出来一些思路,抛砖引玉,希望听听大神们的看法。
先讲故事:我们的云环境是用OpenStack搭建,然后就发现在上面跑虚拟集群的时候,并不能通过Ceilometer知道实际集群中VM-VM的网络通信状态,因为Ceilometer的信息里只有每个VM的出入流量。所以我13年在美国思科实习的时候写了一个CeilometerAgent,通过拿OVS的DB数据得到VM-VM的Flow随时间变化的流量信息。通过这个实际上就得到了集群内的流量矩阵,通过简单的可视化,可以看到虚拟集群的通信pattern和状态。这部分工作在2014年的OepnStackSummit(Atlanta)分享了。
例如下面这个图里,外圈都是VM的ID,每条线代表的一个VM-VM的Flow,其实应该是双向各一条,为了可视化方便合并了。颜色粗细什么的可以根据流量做区分,像这个图就比较清楚是一对多的通信,实际上这是一个Hadoop集群的某一时刻的流量。

上面的工作是端到端的网络流量测量,没有涉及到SDN,也没有实际网络链路上的状态。所以我们做了ScoutFlow,利用OpenFlow流表,把一些特定的flow从交换机上Mirror出来,通过对比得到这条流在某个链路或者path上的丢包和时延,大致思路如下图,蓝色是下发的flow mirror 流表项,红色是Mirror出来的Packet trace:
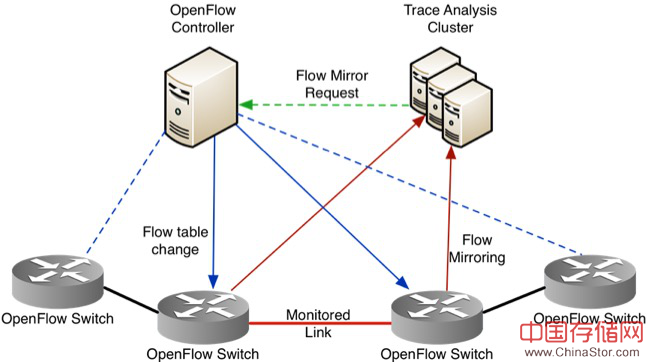
这个工作的目的是两部分,第一可以用于测量网络中的一些关键流量的逐跳性能,第二可以结合前面的OVS 端到端测量,拿到全网的各链路上的性能估算(具体方法是典型的Tomography问题,本质上就是解方程组,不过有些tricky的地方)。
这里比较大的一个挑战是Mirror出来的packet trace数据量会比较大,我们是用下面的一套框架进行数据的实时和准实时处理:
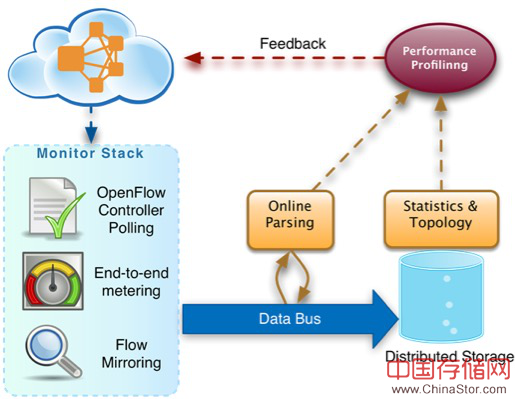
上图中的组件我们实际部署时都是用的开源的,Data Bus 用的Kafka,Online Parsing是用Storm,这是最主要的部分,用于处理mirror出来的packet trace并计算业务的逐跳延迟和丢包,之后的结果和后期的分析放到Hadoop上。还有一些压缩之后的数据,为了方便处理我用R来做的(主要是画图好看 - -)。
Q&A
Q1:时延和抖动你都没测 拿iperf和ping测性能??? seriouslyLatency analysis呢?
A1:Latency的获得是通过mirror的报文时间差拿到的,不是用iperf和ping
Q2:大神,如何测端到端时延?
A2:利用Flow Mirror测量的时延是逐跳的,不是端到端的,如果测端到端时延,确实要考虑rtt和同步的问题
Q3:请问你设置的性能指标是什么
A3:我们主要测量网络中某个业务的流的逐跳的延迟和丢包
Q4:上面图中的disitribute storage,你指什么?
A4:Distribute Storage是HDFS
Q5:你认为拥塞,一般会发生在转发设备端口还是会发生在链路上,这个有诊断方法吗?
A5:拥塞我认为主要是发生在转发端口上(在一般情况下),很多研究工作里的链路拥塞实际上可以看成一种抽象描述。
Q6:上面图里面的feadback怎么理解?
A6:一方面,是通过端到端的测量寻找网络中的故障点,然后去调用ScoutFlow中的API来Mirror我们关心的流。另一方面,Feedback control是我们下一步的打算,主要是考虑拥塞控制和workload调度。
--------------------------------------------------------------------------
SDN实战团微信群由Brocade中国区CTO张宇峰领衔组织创立,携手SDN Lab以及海内外SDN/NFV/云计算产学研生态系统相关领域实战技术牛,每周都会组织定向的技术及业界动态分享,欢迎感兴趣的同学加微信:eigenswing,进群参与,您有想听的话题可以给我们留言。