【编者的话】本文回顾总结近一段时间网易云音乐机器学习平台(GoblinLab)在容器化实践的一些尝试。
背景
过去音乐算法的模型训练任务,是在物理机上进行开发、调试以及定时调度。每个算法团队使用属于自己的独立物理机,这种现状会造成一些问题。比如物理机的分布零散,缺乏统一的管理,主要依赖于doc文档的表格记录机器的使用与归属;各业务间机器资源的调配,有时需要机器在不同机房的搬迁,耗时耗力。另外,由于存在多人共用、开发与调度任务共用等情况,会造成环境的相互影,以及资源的争夺。针对当前的情况,总结问题如下:
资源利用率低:部分机器资源利用率偏低;无法根据各个业务的不同阶段,在全局内快速、动态的实现扩缩容,以达到资源的合理配置,提升资源整体利用率; 环境相互影响:存在多人共用、测试与调度混用同一开发机,未做任何的隔离,造成可能的环境、共享资源的相互影响与争夺; 监控报警缺失:物理机模式,任务监控报警功能缺失,导致任务无法运维,或者效率低。
资源没有全局统一的合理调配,会出现负载不均衡,资源不能最大化的利用。
Kubernetes的尝试
在快速的扩缩容、环境隔离、资源监控等方面,Kubernetes及其相关扩展,可以很好的解决问题。现将物理机集中起来,并构建成一个Kubernetes集群。通过分析算法同事以往的工作方式,机器学习平台(GoblinLab)决定尝试基于Kubernetes提供在线的开发调试容器环境以及任务的容器化调度两种方案,其分别针对任务开发和任务调度两种场景。
任务开发
为最大化的减少算法同事由物理机迁移到容器化环境的学习成本,GoblinLab系统中基本将Kubernetes的容器当做云主机使用。容器的镜像以各版本Tensoflow镜像为基础(底层是Ubuntu),集成了大数据开发环境(Hadoop、Hive、Spark等Client),安装了常用的软件。另外,为了方便使用,容器环境提供了Jupyter Lab、SSH登录、Code Server(VSCode)三种使用方式。
在GoblinLab中新建容器化开发环境比较简单,只需选择镜像,填写所需的资源,以及需要挂载的外部存储即可(任务开发的环境下文简称开发实例)。
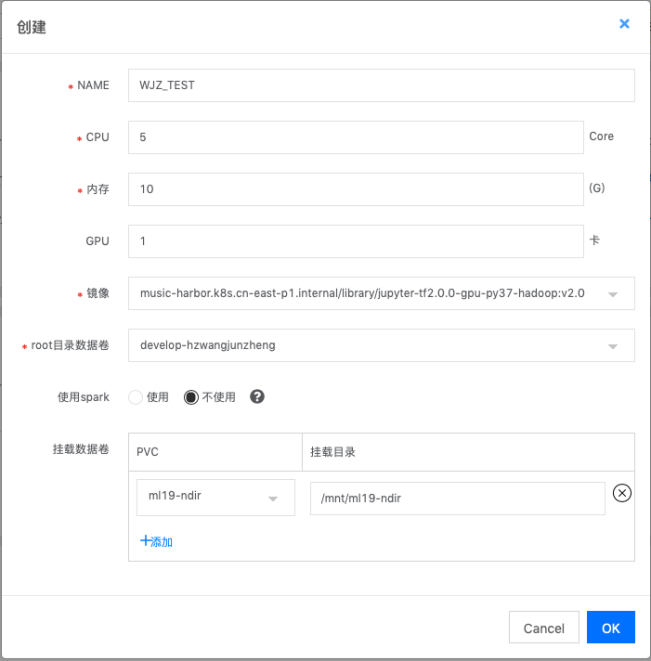
新建环境配置后,点击启动实例,容器初始化时,会自动启动Jupyter lab、SSH以及CodeServer。
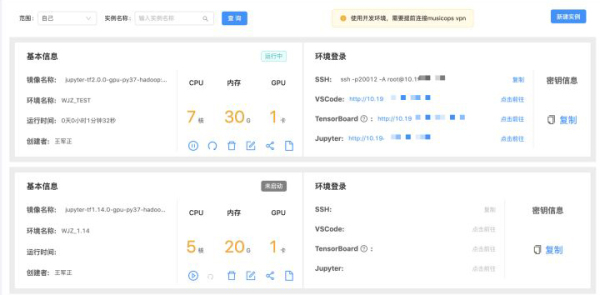
Jupyter Lab:
Code Server:
SSH登录:

算法可以选择以上任意一种方式进行任务的开发,或者调试。由于提供了Code Server(VSCode),所以可以获得更好的体验。
任务开发所用的容器化环境,在底层Kubernetes上是通过StatefulSet类型实现,对应资源编排文件如下(已精简细节):
kind: StatefulSet apiVersion: apps/v1 metadata: name: ${name} namespace: "${namespace}" spec: replicas: 1 selector: matchLabels: statefulset: ${name} system/app: ${name} template: spec: <#if (gpu > 0)> tolerations: - effect: NoSchedule key: nvidia.com/gpu value: "true" <#if usePrivateRepository == "true"> imagePullSecrets: - name: registrykey-myhub volumes: - name: localtime hostPath: path: /etc/localtime <#if MountPVCs?? && (MountPVCs?size > 0)> <#list MountPVCs?keys as key> - name: "${key}" persistentVolumeClaim: claimName: "${key}" containers: - name: notebook image: ${image} imagePullPolicy: IfNotPresent volumeMounts: - name: localtime mountPath: /etc/localtime <#if readMountPVCs?? && (readMountPVCs?size > 0)> <#list readMountPVCs?keys as key> - name: "${key}" mountPath: "${readMountPVCs[key]}" readOnly: true <#if writeMountPVCs?? && (writeMountPVCs?size > 0)> <#list writeMountPVCs?keys as key> - name: "${key}" mountPath: "${writeMountPVCs[key]}" env: - name: NOTEBOOK_TAG value: "${name}" - name: HADOOP_USER value: "${hadoopUser}" - name: PASSWORD value: "${password}" resources: requests: cpu: ${cpu} memory: ${memory}Gi <#if (gpu > 0)> nvidia.com/gpu: ${gpu} limits: cpu: ${cpu} memory: ${memory}Gi <#if (gpu > 0)> nvidia.com/gpu: ${gpu}
目前GolbinLab已提供基于Tensoflow各版本的CPU与GPU通用镜像11个,以及多个定制化镜像。
任务调度
算法同事在使用容器化环境之前,任务的开发调度都是在GPU物理机器上完成,调度一般都是通过定时器或crontab命令调度任务,任务无失败、超时等报警,以及也没有重试等机制,基本无相关的任务运维工具。
在介绍容器中开发的任务如何上线调度之前,先简要介绍一下GoblinLab的系统架构。
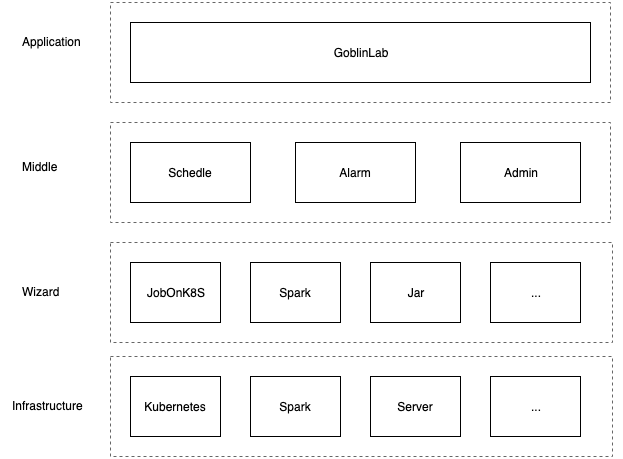
上图为GoblinLab简化的系统架构,其中主要分为四层,由上到下分别为:
Application-应用层:提供直接面向用户的机器学习开发平台(GoblinLab) Middle-中间层: 中间层,主要是接入了统一的调度、报警、以及配置等服务 Wizard-执行服务: 其提供统一的执行服务,提供包含Kubernetes、Spark、Jar等各类任务的提交执行。插件式,支持快速扩展 Infrastructure-基础设施: 底层的基础设施,主要包含Kubernetes集群、Spark集群以及普通服务器等
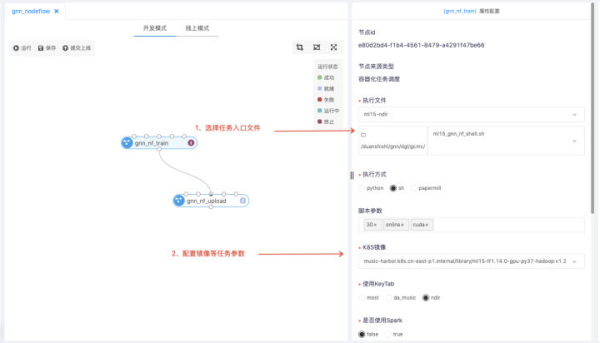
GolbinLab为了保障调度任务的稳定性,将任务的开发与调度拆分,改变之前算法直接在物理机上开发完任务后,通过定时器或者crontab调度任务的方式。如上图所示,在开发完成后,任务的调度是通过任务流中的容器化任务调度组件实现,用户需填组件的相关参数(代码所在PVC及路径,配置镜像等),再通过任务流的调度功能实现任务调度。与任务开发不同,每个调度任务执行在独立的容器中,保证任务间相互隔离,同时通过后续介绍的资源隔离方案,可以优先保障线上调度任务所需资源。

任务调度执行的一般流程如下:

任务调度执行时在Kubernetes上资源编排文件(已精简细节):
apiVersion: batch/v1 kind: Job metadata: name: ${name} namespace: ${namespace} spec: template: spec: containers: - name: jupyter-job image: ${image} env: - name: ENV_TEST value: ${envTest} command: ["/bin/bash", "-ic", "cd ${workDir} && ${execCommand} /root/${entryPath} ${runArgs}"] volumeMounts: - mountPath: "/root" name: "root-dir" resources: requests: cpu: ${cpu} memory: ${memory}Gi <#if (gpu > 0)> nvidia.com/gpu: ${gpu} limits: cpu: ${cpu} memory: ${memory}Gi <#if (gpu > 0)> nvidia.com/gpu: ${gpu} volumes: - name: "root-dir" persistentVolumeClaim: claimName: "${pvc}" backoffLimit: 0
权限控制
容器化开发环境配置启动后,用户可以通过SSH登录、CodeServer或JupyterLab等其中一种方式使用。为了避免容器化开发环境被其他人使用,GoblinLab给每种方式都设置了统一的密钥,而密钥在每次启动时随机生成。
1、随机生成密码
2、设置账号密码(SSH登录密码)
echo "root:${password}" | chpasswd
3、设置Code Server密码 (VSCode)
#设置环境变量PASSWORD即可 env: - name: PASSWORD value: "${password}"
4、设置Jupyter Lab密码
jupyter notebook --generate-config,~/.jupyter 目录下生成jupyter_notebook_config.py,并添加代码 import os from IPython.lib import passwd c = c # pylint:disable=undefined-variable c.NotebookApp.ip = '0.0.0.0' # https://github.com/jupyter/notebook/issues/3946 c.NotebookApp.port = int(os.getenv('PORT', 8888)) c.NotebookApp.open_browser = False sets a password if PASSWORD is set in the environment if 'PASSWORD' in os.environ: password = os.environ['PASSWORD'] if password: c.NotebookApp.password = passwd(password) else: c.NotebookApp.password = '' c.NotebookApp.token = '' del os.environ['PASSWORD']
数据持久化
在Kubernetes容器中,如无特殊配置,容器中的数据是没有进行持久化,这意味着随着容器的删除或者重启,数据就会丢失。对应的解决方法比较简单,只需给需要持久化的目录,挂载外部存储即可。在GoblinLab中,会给每个用户自动创建一个默认的外部存储PVC,并挂载到容器的/root目录。另外,用户也可以自定义外部存储的挂载。
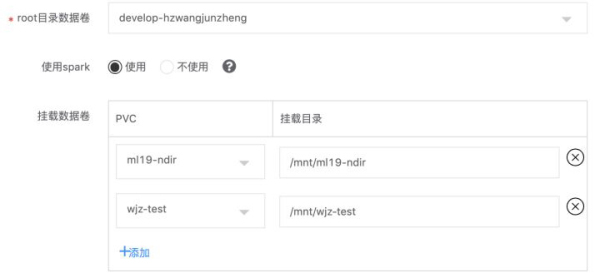
除了自动创建的PVC外,用户也可以自己创建PVC,并支持将创建的PVC只读或者读写分享给其他人。
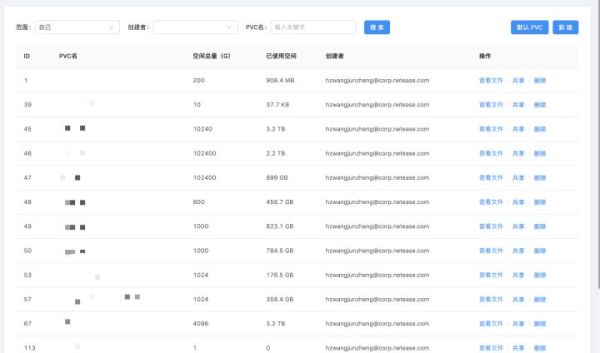
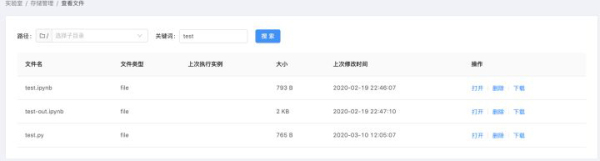
另外,在Goblinlab上也可以对PVC里的数据进行管理。
服务暴露
Kubernetes集群中创建的服务,在集群外无法直接访问,GoblinLab使用Nginx Ingress + Gateway访问,将集群内的服务暴露到外部。
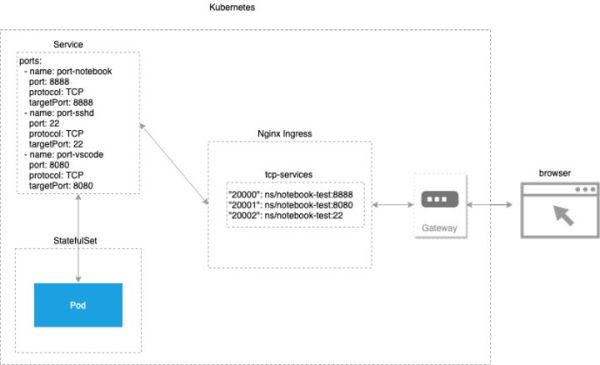
容器化开发环境的Service资源编排文件如下(已精简细节):
apiVersion: v1 kind: Service metadata: name: ${name} namespace: ${namespace} spec: clusterIP: None ports: - name: port-notebook port: 8888 protocol: TCP targetPort: 8888 - name: port-sshd port: 22 protocol: TCP targetPort: 22 - name: port-vscode port: 8080 protocol: TCP targetPort: 8080 - name: port-tensofboard port: 6006 protocol: TCP targetPort: 6006 <#if ports?? && (ports?size > 0)> <#list ports as port> - name: port-${port} port: ${port} targetPort: ${port} selector: statefulset: ${name} type: ClusterIP
每当用户启动一个容器化开发环境,GoblinLab将通过接口自动修改Nginx Ingress配置,将服务暴露出来,以供用户使用,Ingress转发配置如下:
apiVersion: v1 kind: ConfigMap metadata: name: tcp-services namespace: kube-system data: "20000": ns/notebook-test:8888 "20001": ns/notebook-test:8080 "20002": ns/notebook-test:22
资源管控
为提高资源的利用率,GoblinLab底层Kubernetes中的资源,基本都是以共享的方式使用,并进行一定比例的超售。但是当多个团队共享一个资源总量固定的集群时,为了确保每个团队公平的共享资源,此时需要对资源进行管理和控制。在Kubernetes中,资源配额就是解决此问题的工具。目前GoblinLab需要管控的资源主要为CPU、内存、GPU以及存储等。平台在考虑各个团队的实际需求后,将资源划分为多个队列(Kubernetes中的概念为namespace),提供给各个团队使用。
apiVersion: v1 kind: ResourceQuota metadata: name: skiff-quota namespace: test spec: hard: limits.cpu: "2" limits.memory: 5Gi requests.cpu: "2" requests.memory: 5Gi requests.nvidia.com/gpu: "1" requests.storage: 10Gi
在集群中,最常见的资源为CPU与内存,由于可以超售(overcommit),所以存在limits与requests两个配额限制。除此以外,其他资源为扩展类型,由于不允许overcommit,所以只有requests配额限制。参数说明:
limits.cpu:Across all pods in a non-terminal state, the sum of CPU limits cannot exceed this value. limits.memory: Across all pods in a non-terminal state, the sum of memory limits cannot exceed this value. requests.cpu:Across all pods in a non-terminal state, the sum of CPU requests cannot exceed this value. requests.memory:Across all pods in a non-terminal state, the sum of memory requests cannot exceed this value. http://requests.nvidia.com/gpu:Across all pods in a non-terminal state, the sum of gpu requests cannot exceed this value. requests.storage:Across all persistent volume claims, the sum of storage requests cannot exceed this value.
可以进行配额控制的资源不仅有CPU、内存、存储、GPU,其他类型参见官方文档:https://kubernetes.io/docs/con ... otas/
资源隔离
GoblinLab的资源隔离,指的是在同一Kubernetes集群中,资源在调度层面的相对隔离,其中包含GPU机器资源的隔离、线上与测试任务的隔离。
GPU机器资源的隔离
在Kubernetes集群中,相对于CPU机器,GPU机器资源较为珍贵,因此为了提供GPU的利用率,禁止CPU任务调度在GPU机器上。
GPU节点设置污点(Taint):禁止一般任务调度在GPU节点
key: nvidia.com/gpu value: true effect: NoSchedule
Taint的effect可选配置:
NoSchedule:Pod不会被调度到标记为taints节点。 PreferNoSchedule:NoSchedule的软策略版本。尽量避免将Pod调度到存在其不能容忍taint的节点上。 NoExecute:该选项意味着一旦Taint生效,如该节点内正在运行的Pod没有对应Tolerate设置,会直接被逐出。
GPU任务设置容忍(Toleration):让GPU任务可以调度在GPU节点
<#if (gpu > 0)> tolerations: - effect: NoSchedule key: nvidia.com/gpu value: "true"
线上与测试任务隔离
线上与测试任务(GolbinLab中线上任务与测试任务为业务层面的定义,指的是周期调度任务和开发测试任务)使用同一Kubernetes集群,但为了保障线上任务的资源,会特殊设置一些机器节点为线上任务的专有资源池。线上任务执行时优先调度在线上节点上,线上资源池无资源时,也可调度于非线上节点。
线上资源池节点设置污点(Taint):禁止一般任务调度在线上资源池
key: node.netease.com/node-pool value: online effect: NoSchedule
线上任务添加容忍(Toleration):允许线上任务调度于线上资源池,但不是必须调度于线上资源池中
tolerations: - effect: NoSchedule key: node.netease.com/node-pool value: "online" operator: Equal
线上资源池中机器节点设置标签 + 线上任务设置节点亲和性(nodeAffinity):优先将线上任务调度在线上资源池中,但如果线上资源池中无已资源,此时也可以调度在其他节点上
线上资源池中节点设置标签:为了方便,标签与污点同名:
node.netease.com/node-pool: online
线上任务设置节点亲和性(nodeAffinity):线上任务优先调度在线上资源池中
affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: node.netease.com/node-pool operator: In values: - online
目前Node affinity有以下几种策略,官方文档affinity-and-anti-affinity:
requiredDuringSchedulingIgnoredDuringExecution表示Pod必须部署到满足条件的节点上,如果没有满足条件的节点,就不停重试。其中IgnoreDuringExecution表示Pod部署之后运行的时候,如果节点标签发生了变化,不再满足Pod指定的条件,Pod也会继续运行。 requiredDuringSchedulingRequiredDuringExecution表示Pod必须部署到满足条件的节点上,如果没有满足条件的节点,就不停重试。其中RequiredDuringExecution表示Pod部署之后运行的时候,如果节点标签发生了变化,不再满足Pod指定的条件,则重新选择符合要求的节点。 preferredDuringSchedulingIgnoredDuringExecution表示优先部署到满足条件的节点上,如果没有满足条件的节点,就忽略这些条件,按照正常逻辑部署。 preferredDuringSchedulingRequiredDuringExecution表示优先部署到满足条件的节点上,如果没有满足条件的节点,就忽略这些条件,按照正常逻辑部署。其中RequiredDuringExecution表示如果后面节点标签发生了变化,满足了条件,则重新调度到满足条件的节点。
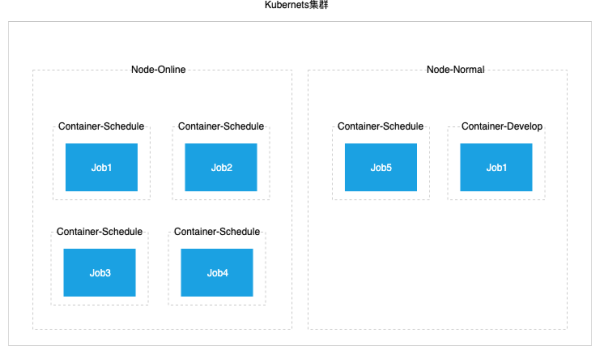
策略生效后效果如下图所示, 线上任务优先执行与线上资源池节点中,但当线上资源池没有空闲资源后,线上任务Job5也可以去使用普通节点的资源。
阶段性结果
截止今日,音乐机器学习平台(GoblinLab)在容器化方面的尝试,已开展了一段时间,并且已经有了阶段性的成果。
集群建设
经过近一段时间的尝试,目前音乐数据平台的Kubernetes,随着承载的业务越来越多,以及基于Kubernetes的大数据计算平台(Flink等)的落地,后续将有大量的CPU资源加入, 其稳定性将会成为比较大的挑战。
用户使用
任务迁移:目前协助算法同事已完成80%任务迁移
任务开发
用户情况 : 已有60%算法同学使用开发实例的容器化环境;其中用户来源包含音乐推荐算法、社交视频推荐算法、搜索算法、音视频、数据应用、实时计算算法等团队 开发实例:平台鼓励组内共用开发实例,限制了每人最多创建3个开发实例 任务调度: 覆盖云音乐音乐推荐、社交视频推荐算法、搜索算法、音视频、数据应用、实时计算算法等多个团队
容器化的好处
对于算法同事,由物理机迁移到机器学习平台提供容器化的环境,能够带来的好处是:
更多资源:由于整理资源利用率的提高,将有机会获取到比之前单独使用物理机更多的资源;另外资源扩缩容的周期由之前的以天为单位减少到秒级别即可完成 更好体验:通过打通大数据、Git环境,提供多样化的使用方式(SSH和在线IDE),由机器学习平台统一维护环境镜像,避免了每个团队需自己搭建、运维环境的苦恼 更完善的任务调度:GoblinLab的调度,提供了更完善的报警、重试、依赖检查等功能,并且能够与之前已有PS、Ironbaby任务的整合,实现在一个任务流的统一调度 更好的隔离:环境隔离是容器化的天然优势。另外资源在调度层面的隔离,可以更好的保障线上任务 统一的入口:统一了开发的入口后,可以有更大的操作空间。例如将通用的服务抽象后由平台直接提供(依赖检查、调度、报警监控等等)、数据的共享、镜像的更新以及后面持续的支持服务等 后续规划
目前音乐机器学习平台已能提供完整的容器化开发基础能力,为进一步提高集群的资源利用率、提升运维效率,后续计划从资源调度策略优化(抢占等)、更丰富的资源监控等方面入手,进一步优化。
作者:网易云音乐数据智能部数据平台组王军正