简介
IBM PowerHA System Mirror for AIX 是集群软件,使得资源或资源组(应用程序)能够在出现系统故障时自动或手动转移到另一个 IBM AIX® 系统。
对于集群中的所有可用接口,将执行心跳和故障检查。这些接口可以是网络接口、光纤通道 (FC) 适配器接口和 Cluster Aware AIX (CAA) 存储库磁盘。
在 PowerHA 6.1 及早期版本中,不支持基于 FC 适配器接口的心跳功能,相反,为所有节点提供了与 SAN 有关的心跳磁盘,这样做是为了实现心跳和故障检测。在 PowerHA 7.1 中,不再支持使用心跳磁盘,取而代之的是基于 SAN 的心跳。
为了实现基于 SAN 的心跳,需要对 AIX 系统中的 FC 适配器进行配置,使其充当目标 和发起方 (initiator)。在大多数 SAN 环境中,发起方设备通常属于作为主机总线适配器 (HBA) 的服务器,而目标通常是一个存储设备,比如存储控制器或磁带设备。IBM AIX 7.1 Information Center 提供了可以支持目标节点 的 FC 适配器的完整列表。这些适配器可用于基于 SAN 的心跳。
概述
在本文中,我提供了简单的示例,演示了如何在两个场景中设置 SAN 心跳:第一个示例使用了两个采用物理 I/O 的 AIX 系统,另一个示例使用了两个采用 Virtual I/O Server 和 N-Port ID Virtualization (NPIV) 的 AIX 逻辑分区 (LPAR)。
在每个例子中,我们配置了一个两节点的 PowerHA 7.1 集群,其中一个节点位于不同的基于 IBM POWER® 处理器的服务器。本文不会介绍如何配置共享存储、高级网络通信或应用程序控件,而将实际演示如何构建一个非常简单的集群并使 SAN 心跳正常运行。
要求
- 必须满足下面列出的最低要求才能确保成功创建集群并配置 SAN 心跳:
- 需要在两个 AIX 系统上安装 AIX 6.1,7.1 更佳,使用最新的技术水平和服务包。
- 需要在两个 AIX 系统上安装 PowerHA 7.1,使用最新的服务包。
- 服务器上的 FC 适配器必须支持目标模式,如果使用了 NPIV,则必须采用 8 GBps 适配器支持 NPIV。需要满足 NPIV 支持才能实现本文后面介绍的场景 2。
- 如果使用了 Virtual I/O Server,那么 VIOS 代码应当是最新服务包 IOS 2.2。这是本文场景 2 中的必要条件。
- 如果使用了 NPIV,那么光纤交换机必须启用 NPIV 支持,并且具有受支持的固件。这也是本文第 2 个场景的必要条件。
- 必须为 AIX 系统分配一个逻辑单元号 (LUN),以便将它作为 CAA 存储库磁盘使用。
- 必须为两个 AIX 系统分配一个 LUN,为集群实现共享存储。
场景 1:两个节点使用物理 I/O
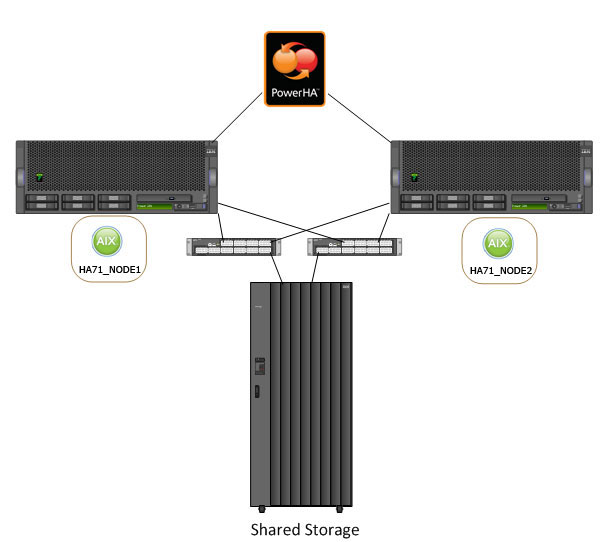
在本场景中,我们设置了一个非常简单的环境,其中有两个基于 POWER 处理器的系统,每个系统有一个 AIX 实例。这些系统位于一个 PowerHA 集群中,并通过冗余的 SAN 光纤连接到共享存储。
下图从较高的层面概括了这一场景。
图 1. 场景 1 概览
SAN 分区要求
在创建集群之前,需要进行 SAN 分区。您需要配置以下两种类型的分区。
- 存储分区
- 心跳分区
要配置分区,首先需要登录到每一个节点中,检查 FC 适配器是否可用,然后捕捉每个适配器端口的全球端口号 (WWPN),如下例所示。
root@ha71_node1:/home/root# lsdev -Cc adapter |grep fcs
fcs0 Available 02-T1 8Gb PCI Express Dual Port FC Adapter
fcs1 Available 03-T1 8Gb PCI Express Dual Port FC Adapter
fcs2 Available 02-T1 8Gb PCI Express Dual Port FC Adapter
fcs3 Available 03-T1 8Gb PCI Express Dual Port FC Adapter
root@ha71_node1:/home/root# for i in `lsdev -Cc adapter |awk '{print $1}'
|grep fcs `; do print ${i} - $(lscfg -vl $i |grep Network |awk '{print $2}'
|cut -c21-50| sed 's/../&:/g;s/:$//'); done
fcs0 - 10:00:00:00:C9:CC:49:44
fcs1 - 10:00:00:00:C9:CC:49:45
fcs2 - 10:00:00:00:C9:C8:85:CC
fcs3 - 10:00:00:00:C9:C8:85:CD
root@ha71_node1:/home/root#
root@ha71_node2:/home/root# lsdev -Cc adapter |grep fcs
fcs0 Available 02-T1 8Gb PCI Express Dual Port FC Adapter
fcs1 Available 03-T1 8Gb PCI Express Dual Port FC Adapter
fcs2 Available 02-T1 8Gb PCI Express Dual Port FC Adapter
fcs3 Available 03-T1 8Gb PCI Express Dual Port FC Adapter
root@ha71_node2:/home/root# for i in `lsdev -Cc adapter |awk '{print $1}'
|grep fcs `; do print ${i} - $(lscfg -vl $i |grep Network |awk '{print $2}'
|cut -c21-50| sed 's/../&:/g;s/:$//'); donefcs0 - 10:00:00:00:C9:A9:2E:96
fcs1 - 10:00:00:00:C9:A9:2E:97
fcs2 - 10:00:00:00:C9:CC:2A:7C
fcs3 - 10:00:00:00:C9:CC:2A:7D
root@ha71_node2:/home/root#
在获得 WWPN 后,就可以在光纤交换机上执行分区。将 HBA 适配器分到共享存储使用的存储控制器的存储端口,同时创建可用于心跳的分区。下图概述了如何创建心跳分区。
图 2. 创建心跳分区(场景 1)
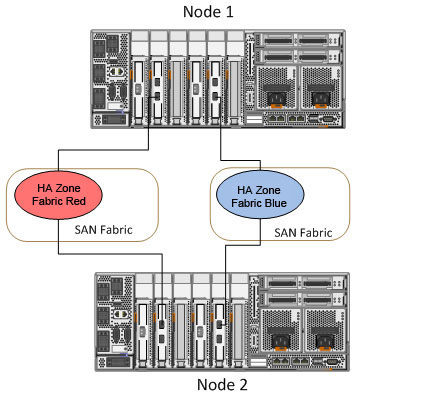
确保您已经将第一个节点上每个 FC 适配器的一个端口分给第二个节点上每个 FC 适配器的另一个端口。
AIX 中的设备配置
完成分区后,下一步是在 AIX 的每个适配器设备上启用目标模式。您需要在用于心跳分区的每个适配器上执行这一步。在 SAN 分区示例中,每个节点上的适配器 fcs0 和 fcs2 都用于 SAN 心跳分区。
要启用目标模式,则需要在 fscsi 设备上同时启用 dyntrk(动态跟踪)和 fast_fail,而在 fcs 设备上,则需要启用目标模式。
要启用 目标模式,则需要在分区的所有节点上执行以下步骤。
root@ha71_node1:/home/root# rmdev –l fcs0 –R fscsi0 Defined fcs0 Defined root@ha71_node1:/home/root# rmdev –l fcs2 –R fscsi2 Defined fcs2 Defined root@ha71_node1:/home/root# chdev –l fscsi0 –a dyntrk=yes -a fc_err_recov=fast_fail fscsi0 changed root@ha71_node1:/home/root# chdev –l fscsi2 –a dyntrk=yes –a fc_err_recov=fast_fail fscsi2 changed root@ha71_node1:/home/root# chdev –l fcs0 -a tme=yes fcs0 changed root@ha71_node1:/home/root# chdev –l fcs2 -a tme=yes fcs2 changed root@ha71_node1:/home/root# cfgmgr root@ha71_node1:/home/root#
root@ha71_node2:/home/root# rmdev –l fcs0 –R fscsi0 Defined fcs0 Defined root@ha71_node2:/home/root# rmdev –l fcs2 –R fscsi2 Defined fcs2 Defined root@ha71_node2:/home/root# chdev –l fscsi0 –a dyntrk=yes –a fc_err_recov=fast_fail fscsi0 changed root@ha71_node2:/home/root# chdev –l fscsi2 –a dyntrk=yes –a fc_err_recov=fast_fail fscsi2 changed root@ha71_node2:/home/root# chdev –l fcs0 -a tme=yes fcs0 changed root@ha71_node2:/home/root# chdev –l fcs2 -a tme=yes fcs2 changed root@ha71_node2:/home/root# cfgmgr root@ha71_node2:/home/root#
如果设备繁忙,那么可以在命令结尾使用 –P 选项进行修改,然后重启服务器。这将在服务器下一次启动时让更改生效。
目标模式 的设置可以通过检查 fscsi 设备的属性进行验证。下面的示例演示了如何检查其中一个节点上的 fscsi0 和 fcs0。应当在两个节点上的每个 fcs0 和 fcs2 适配器上进行这种检查。
root@ha71_node1:/home/root# lsattr -El fscsi0 attach switch How this adapter is CONNECTED False dyntrk yes Dynamic Tracking of FC Devices True fc_err_recov fast_fail FC Fabric Event Error RECOVERY Policy True scsi_id 0xbc0e0a Adapter SCSI ID False sw_fc_class 3 FC Class for Fabric True root@ha71_node1:/home/root# lsattr -El fcs0 |grep tme tme yes Target Mode Enabled True root@ha71_node1:/home/root#
启用目标模式 后,接下来应当查找可用的 sfwcomm 设备。这些设备用于 PowerHA 错误检测和基于 SAN 的心跳。
检查这些设备是否在所有节点上均可用。
root@ha71_node1:/home/root# lsdev -C |grep sfwcomm sfwcomm0 Available 02-T1-01-FF Fibre Channel Storage Framework Comm sfwcomm1 Available 03-T1-01-FF Fibre Channel Storage Framework Comm sfwcomm2 Available 02-T1-01-FF Fibre Channel Storage Framework Comm sfwcomm3 Available 03-T1-01-FF Fibre Channel Storage Framework Comm root@ha71_node1:/home/root#
root@ha71_node1:/home/root# lsdev -C |grep sfwcomm sfwcomm0 Available 02-T1-01-FF Fibre Channel Storage Framework Comm sfwcomm1 Available 03-T1-01-FF Fibre Channel Storage Framework Comm sfwcomm2 Available 02-T1-01-FF Fibre Channel Storage Framework Comm sfwcomm3 Available 03-T1-01-FF Fibre Channel Storage Framework Comm root@ha71_node1:/home/root#
场景 2:两个节点使用 Virtual I/O Server
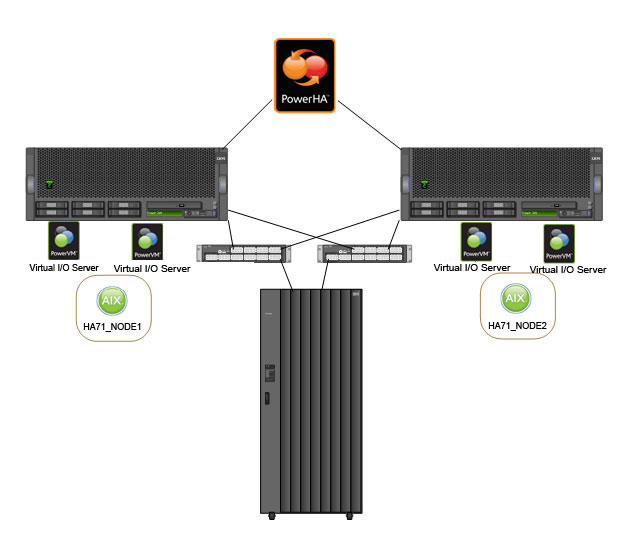
本场景使用了一个略微复杂的环境,有两个基于 POWER 处理器的系统,每个系统都有一个双 VIOS 和使用 VIOS 的 LPAR。这些 LPAR 位于一个 PowerHA 集群中,并通过冗余 SAN 光纤连接到共享存储。
在使用 VIOS 时,与物理 I/O 场景不同的一点是:必须将 Virtual I/O Server 的 FC 端口分配在一起。然后使用一个端口 VLAN ID 为 3358(3358 是将要使用的惟一 VLAN ID)的专用虚拟 LAN(VLAN)来承载 Virtual I/O Server 到客户端 LPAR(即我们的 PowerHA 节点)之间的心跳通信(基于管理程序)。
在这种情况下,需要执行以下高级步骤。
- 在 VIOS FC 适配器上启用 目标 模式。
- 将 VIOS 端口分在同一区。
- 针对心跳通信配置专用 3358 VLAN。
- 配置 PowerHA 集群。
下图从较高的层面概括了这一场景。
图 3. 场景 2 概述
SAN 分区需求
在创建集群前,需要进行 SAN 分区。您需要配置下面两种分区。
- 存储分区
- 包含 LPAR 的虚拟 WWPN
- 包含存储控制器的 WWPN
- 心跳分区(包含 VIOS 物理 WWPN)
- 每个机器上的 VIOS 都应当分在一起。
- 客户端 LPAR 的虚拟 WWPN 不应当分在一起。
在执行分区时,登录到每个 VIOS(所有 VIOS 都在各自的托管系统中),并查看 FC 适配器是否可用,然后捕捉有关分区的 WWPN 信息。下面的示例展示了如何在一个 VIOS 上执行这一步骤。
$ lsdev -type adapter |grep fcs
fcs0 Available 02-T1 8Gb PCI Express Dual Port FC Adapter
fcs1 Available 03-T1 8Gb PCI Express Dual Port FC Adapter
fcs2 Available 02-T1 8Gb PCI Express Dual Port FC Adapter
fcs3 Available 03-T1 8Gb PCI Express Dual Port FC Adapter
$ for i in `lsdev -type adapter |awk '{print $1}' |grep fcs `;
do print ${i} - $(lsdev -dev $i -vpd
|grep Network |awk '{print $2}' |sed 's/Address.............//g'
| sed 's/../&:/g;s/:$//'); done
fcs0 - 10:00:00:00:C9:B7:65:32
fcs1 - 10:00:00:00:C9:B7:65:33
fcs2 - 10:00:00:00:C9:B7:63:60
fcs3 - 10:00:00:00:C9:B7:63:61
还需要从存储区的客户端 LPAR 中捕捉虚拟 WWPN。下面的例子展示了如何在两个节点上执行这一步骤。
root@ha71_node1:/home/root# lsdev -Cc adapter |grep fcs
fcs0 Available 02-T1 Virtual Fibre Channel Client Adapter
fcs1 Available 03-T1 Virtual Fibre Channel Client Adapter
fcs2 Available 02-T1 Virtual Fibre Channel Client Adapter
fcs3 Available 03-T1 Virtual Fibre Channel Client Adapter
root@ha71_node1:/home/root# for i in `lsdev -Cc adapter |awk '{print $1}'
|grep fcs `; do print ${i} - $(lscfg -vl $i |grep Network |awk '{print $2}'
|cut -c21-50| sed 's/../&:/g;s/:$//'); done
fcs0 – c0:50:76:04:f8:f6:00:40
fcs1 – c0:50:76:04:f8:f6:00:42
fcs2 – c0:50:76:04:f8:f6:00:44
fcs3 – c0:50:76:04:f8:f6:00:46
root@ha71_node1:/home/root#
root@ha71_node2:/home/root# lsdev -Cc adapter |grep fcs
fcs0 Available 02-T1 Virtual Fibre Channel Client Adapter
fcs1 Available 03-T1 Virtual Fibre Channel Client Adapter
fcs2 Available 02-T1 Virtual Fibre Channel Client Adapter
fcs3 Available 03-T1 Virtual Fibre Channel Client Adapter
root@ha71_node2:/home/root# for i in `lsdev -Cc adapter |awk '{print $1}'
|grep fcs `; do print ${i} - $(lscfg -vl $i |grep Network |awk '{print $2}'
|cut -c21-50| sed 's/../&:/g;s/:$//'); done
fcs0 – C0:50:76:04:F8:F6:00:00
fcs1 – C0:50:76:04:F8:F6:00:02
fcs2 – C0:50:76:04:F8:F6:00:04
fcs3 – C0:50:76:04:F8:F6:00:06
root@ha71_node2:/home/root#
获得 WWPN 后,可以在光纤交换机上进行分区。将 LPAR 的虚拟 WWPN 分给共享存储使用的存储控制器的存储端口,同时创建包含 VIOS 物理端口的分区,该分区将用于实现心跳。下图概述了如何创建心跳分区。
图 4. 创建心跳分区(场景 2)
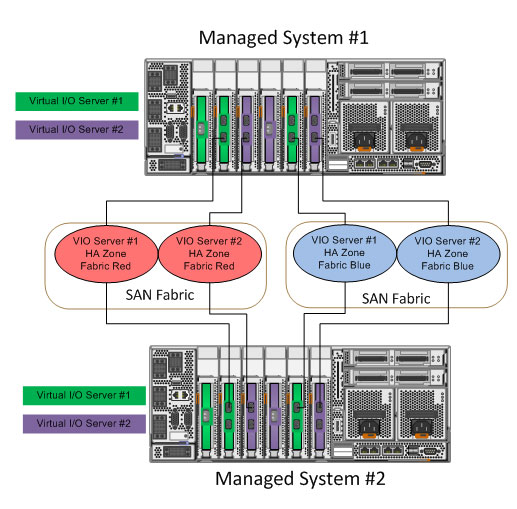
Virtual I/O Server FC 适配器配置
完成分区后,下一步是在每个 VIOS 的每个适配器设备上启用目标模式。您需要在用于心跳分区的每个适配器上执行这一步。在 SAN 分区示例中,每个节点上的适配器 fcs0 和 fcs2 都用于 SAN 心跳分区。
要启用目标模式,则需要在 fscsi 设备上同时启用 dyntrk(动态跟踪)和 fast_fail,而在 fcs 设备上,则需要启用 目标模式。
要启用目标模式,需要在各个托管系统上的 VIOS 上执行以下步骤。
$ chdev -dev fscsi0 -attr dyntrk=yes fc_err_recov=fast_fail –perm fscsi0 changed $ chdev -dev fcs0 -attr tme=yes –perm fcs0 changed $ chdev -dev fscsi2 -attr dyntrk=yes fc_err_recov=fast_fail –perm fscsi2 changed $ chdev -dev fcs2 -attr tme=yes –perm fcs2 changed $ shutdown -restart
您需要重启每个 VIOS,因此强烈建议每次只修改一个 VIOS。
Virtual I/O Server 网络配置
当使用 VIOS 时,属于 VIOS 的物理 FC 适配器会分在一起。这将每个托管系统上的 VIOS 连接在一起,然而,对于客户端 LPAR(HA 模式)连接,必须配置一个专用 VLAN 才能实现连接。
VLAN ID 必须是 3358 才能顺利运行。下图描述了虚拟以太网的设置。
图 5. 虚拟以太网设置

首先,登录到每个 VIOS,向每个共享以太网桥接适配器添加一个额外的 VLAN。这将为 3358 VLAN 提供 VIOS 连接。
下图显示了如何将额外的 VLAN 添加到桥接适配器。
图 6. 向桥接适配器添加额外的 VLAN
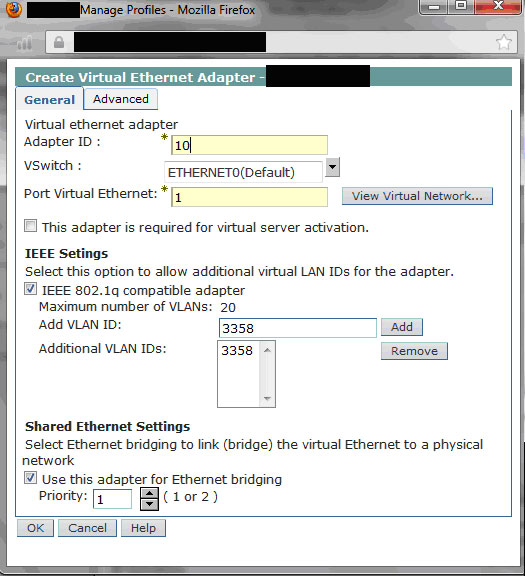
接下来,在客户端分区创建虚拟以太网适配器,然后将端口虚拟 VLAN ID 设为 3358。这为 3358 VLAN 提供了客户端 LPAR 连接。
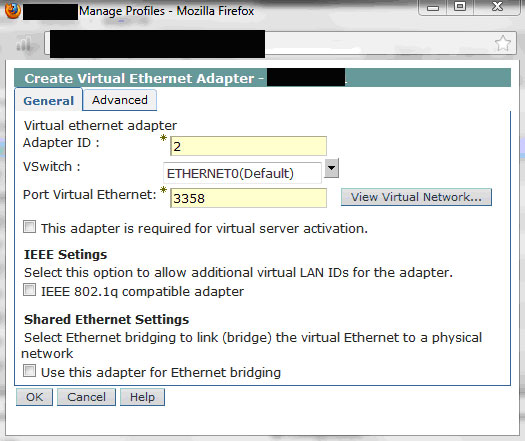
从 AIX 中,运行 cfgmgr 命令并选择虚拟以太网适配器。
不要在这个界面中添加 IP 地址。
图 7. 在客户端分区创建虚拟以太网适配器
完成这一步后,我们就可以创建 PowerHA 集群,并且 SAN 心跳已经准备就绪。
PowerHA 集群配置
在创建集群之前,第一步是执行以下任务:
- 编辑 /etc/environment,并将 /usr/es/sbin/cluster/utilities 和 /usr/es/sbin/cluster/ 添加到 $PATH 变量。
- 填充 /etc/cluster/rhosts。
- 填充 /usr/es/sbin/cluster/netmon.cf。
完成这一步后,可以使用 smitty sysmirror 或在命令行中创建集群。在下面的示例中,我创建了一个简单的两节点集群,名为 ha71_cluster。
root@ha71_node1:/home/root # clmgr add cluster ha71_cluster NODES="ha71_node1 ha71_node2"
Warning: to complete this configuration, a repository disk must be defined.
Cluster Name: ha71_cluster
Cluster Connection Authentication Mode: Standard
Cluster Message Authentication Mode: None
Cluster Message Encryption: None
Use Persistent Labels for Communication: No
Repository Disk: None
Cluster IP Address:
There are 2 node(s) and 1 network(s) defined
NODE ha71_node1:
Network net_ether_01
ha71_node1 172.16.5.251
NODE ha71_node2:
Network net_ether_01
ha71_node2 172.16.5.252
No resource groups defined
Initializing..
Gathering cluster information, which may take a few minutes...
Processing...
….. etc…..
Retrieving data from available cluster nodes. This could take a few minutes.
Start data collection on node ha71_node1
Start data collection on node ha71_node2
Collector on node ha71_node1 completed
Collector on node ha71_node2 completed
Data collection complete
Completed 10 percent of the verification checks
Completed 20 percent of the verification checks
Completed 30 percent of the verification checks
Completed 40 percent of the verification checks
Completed 50 percent of the verification checks
Completed 60 percent of the verification checks
Completed 70 percent of the verification checks
Completed 80 percent of the verification checks
Completed 90 percent of the verification checks
Completed 100 percent of the verification checks
IP Network Discovery completed normally
Current cluster configuration:
Discovering Volume Group Configuration
root@ha71_node1:/home/root #
创建好集群定义后,下一步是检查每个节点上是否有空闲磁盘,因此我们将配置 CAA 存储库。
root@ha71_node1:/home/root# lsdev –Cc disk hdisk0 Available 00-00-01 IBM MPIO FC 2107 hdisk1 Available 00-00-01 IBM MPIO FC 2107 root@ha71_node1:/home/root# lspv hdisk0 000966fa5e41e427 rootvg active hdisk1 000966fa08520349 None root@ha71_node1:/home/root#
root@ha71_node2:/home/root# lsdev –Cc disk hdisk0 Available 00-00-01 IBM MPIO FC 2107 hdisk1 Available 00-00-01 IBM MPIO FC 2107 root@ha71_node2:/home/root# lspv hdisk0 000966fa46c8abcb rootvg active hdisk1 000966fa08520349 None root@ha71_node2:/home/root#
从上例中可以清楚地看到,hdisk1 是节点上的一个空闲磁盘,因此可用于存储库。接下来,修改集群定义,使之包含集群存储库磁盘。我们在两个节点上的空虚磁盘为 hdisk1。
您可以使用 smitty hacmp 或在命令行中完成这一步。下例展示了如何在命令行中执行这个步骤。
root@ha71_node1:/home/root # clmgr modify cluster ha71_cluster REPOSITORY=hdisk1
Cluster Name: ha71_cluster
Cluster Connection Authentication Mode: Standard
Cluster Message Authentication Mode: None
Cluster Message Encryption: None
Use Persistent Labels for Communication: No
Repository Disk: hdisk1
Cluster IP Address:
There are 2 node(s) and 1 network(s) defined
NODE ha71_node1:
Network net_ether_01
ha71_node1 172.16.5.251
NODE ha71_node2:
Network net_ether_01
ha71_node2 172.16.5.252
No resource groups defined
Current cluster configuration:
root@ha71_node1:/home/root #
下一步是检验并同步集群配置。可以通过 smitty hacmp 或命令行完成此操作。下例将展示如何在命令行中同步集群拓扑和资源。
root@ha71_node1:/home/root # cldare -rt
Timer object autoclverify already exists
Verification to be performed on the following:
Cluster Topology
Cluster Resources
Retrieving data from available cluster nodes. This could take a few minutes.
Start data collection on node ha71_node1
Start data collection on node ha71_node2
Collector on node ha71_node2 completed
Collector on node ha71_node1 completed
Data collection complete
Verifying Cluster Topology...
Completed 10 percent of the verification checks
WARNING: Multiple communication interfaces are recommended for networks that
use IP aliasing in order to prevent the communication interface from
becoming a single point of failure. There are fewer than the recommended
number of communication interfaces defined on the following node(s) for
the given network(s):
Node: Network:
---------------------------------- ----------------------------------
ha71_node1 net_ether_01
ha71_node2 net_ether_01
Completed 20 percent of the verification checks
Completed 30 percent of the verification checks
Saving existing /var/hacmp/clverify/ver_mping/ver_mping.log to
/var/hacmp/clverify/ver_mping/ver_mping.log.bak
Verifying clcomd communication, please be patient.
Verifying multicast communication with mping.
Verifying Cluster Resources...
Completed 40 percent of the verification checks
Completed 50 percent of the verification checks
Completed 60 percent of the verification checks
Completed 70 percent of the verification checks
Completed 80 percent of the verification checks
Completed 90 percent of the verification checks
Completed 100 percent of the verification checks
… etc…
Committing any changes, as required, to all available nodes...
Adding any necessary PowerHA SystemMirror entries to
/etc/inittab and /etc/rc.net for IPAT on node ha71_node1.
Adding any necessary PowerHA SystemMirror entries
to /etc/inittab and /etc/rc.net for IPAT on node ha71_node2.
Verification has completed normally.
root@ha71_node1:/home/root #
现在已经配置了一个基本集群,最后一步是检查 SAN 心跳是否启动。
lscluster –i 命令将显示集群接口及其状态。sfwcom (Storage Framework Communication) 接口为 SAN 心跳。
在下面的示例中,我们可以从任意一个节点检查此操作,从而确保 SAN 心跳已经启动。
root@ha71_node1:/home/root # lscluster -i sfwcom Network/Storage Interface Query Cluster Name: ha71_cluster Cluster uuid: 7ed966a0-f28e-11e1-b39b-62d58cd52c04 Number of nodes reporting = 2 Number of nodes expected = 2 Node ha71_node1 Node uuid = 7ecf4e5e-f28e-11e1-b39b-62d58cd52c04 Number of interfaces discovered = 3 Interface number 3 sfwcom ifnet type = 0 ndd type = 304 Mac address length = 0 Mac address = 0.0.0.0.0.0 Smoothed rrt across interface = 0 Mean Deviation in network rrt across interface = 0 Probe interval for interface = 100 ms ifnet flags for interface = 0x0 ndd flags for interface = 0x9 Interface state UP root@ha71_node1:/home/root #
本文将不再介绍集群配置的其余步骤,比如配置共享存储、镜像池、文件收集、应用程序控制器、监视器等等。