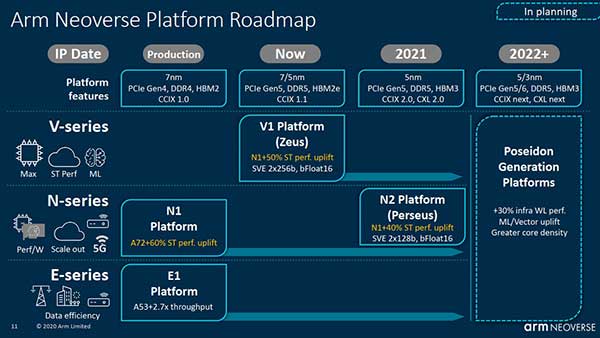
中存储网消息,近日外媒报道,英国半导体设计公司Arm近日发布了其Neoverse产品路线图的详细信息,推出了Arm的第二代N系列平台V1(代号Zeus)和N2(代号Perseus)。芯片IP供应商表示,新平台将比Neoverse N1分别提供50%和40%的单线程性能。
Neoverse V1对可伸缩矢量扩展(SVE)的支持-实现为两个256位宽的矢量-允许在更宽的矢量单元上执行SIMD整数,bfloat16或浮点指令。SVE的设计与单元的宽度无关,因此在一个平台上为SVE编译的应用程序可以在任何有效的SVE实现上运行,该实现可以使用128位至2,048位的宽度(以128位为增量)。
“使用SVE,我们可以确保软件代码的可移植性和寿命以及有效的执行,” Arm的基础设施业务部门高级副总裁兼总经理Chris Bergey说。
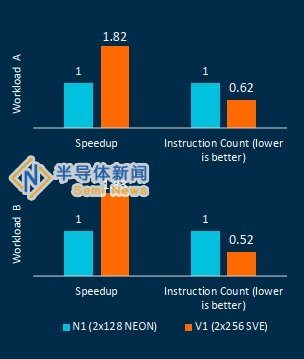
预计的性能提升,较宽的向量可提供更多的应用程序性能
资料来源:Arm
V1 Neoverse核心的新SVE功能借鉴了Arm在A64FX平台上与富士通合作的经验,A64FX平台是世界上排名第一,第一台基于Arm的超级计算机富岳Fugaku的核心,具有SVE功能。
Arm的HPC业务主管Brent Gorda指出,许多Arm合作伙伴正在开发针对数据分析和高性能计算工作负载的基于Neoverse V1的解决方案。其中之一就是SiPearl,它选择了宙斯(Zeus)内核为其第一代服务器处理器提供动力,该处理器是欧洲百亿亿美元计划的基础。
除了超级计算之外,Gorda还引用了SVE在媒体处理,加密/解密,网络处理以及边缘环境中的应用程序。
在上周为媒体举行的预备情况通报中,Arm展示了V1的早期仿真结果,该结果显示在实现级别上比N1更快(请参见上面的条形图)。
Bergey说,硅合作伙伴将完全控制SVE电压和频率转换。正如富士通的A64FX CPU能够做到的那样,这使它们能够在执行SVE代码时全频运行。
伯吉说,Arm继续通过投资CCIX和CXL来推进其互连路线图。
Bergey说,CCIX用于双向相干通信,其使用方式有很多灵活性。
尽管经典情况是多路计算,但小芯片有一个新兴的用例。Bergey说:“您已经听到了好处:芯片尺寸减小,成品率增加,成本降低,并且它使您可以继续增加核心数量和性能。”
Arm还在探索紧密耦合的异构计算。“随着摩尔定律缩放速度的放慢,人们对ARM CPU复合体与各种加速器和内存的芯片间耦合感兴趣,” Bergey说。
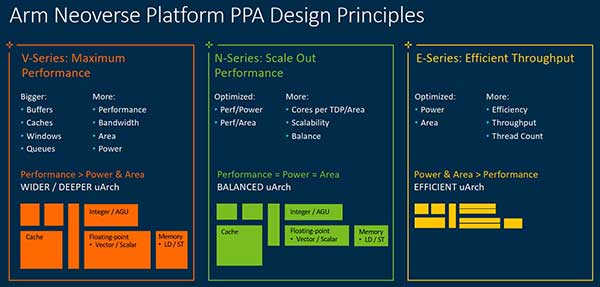
N系列,V系列和E系列的比较(来源:Arm)
该公司还计划提供CXL,以提供内存一致性附件。Bergey强调了用例,“最令人期待的(正在)内存池和扩展”。
他说,它可以“在一组连接的节点之间共享大量内存,或者可能意味着将大量新兴内存附加到单个节点上,”他强调了机器学习训练和推理的好处。
V1强调最苛刻工作负载的最佳性能,而N2强调横向扩展性能。Bergey说:“它不会完全具有V1的每个线程的性能,但是它将在恒定的TDP中支持更多的内核。”
他补充说,虽然每个CPU的内核数量没有硬性限制,但是客户有一个要优化的TDP,它与内核数量目标有关。
“我们正在围绕性能进行优化,以提高功率和每个区域的性能。这样一来,您就可以在每个TDP中打包更多的内核。无论是250瓦的云SOC,还是20瓦的5G基站SOC,”他说。
Arm希望其V1 IP可以在7纳米和5纳米工艺节点上实施,不同的客户可以根据其时限利用这两个节点之一。
Bergey指出,他们为V1和N2预测的性能提升是基于IPC的,与节点无关。
Arm服务器芯片的牵引力继续增加。去年,AWS首次推出了基于N1的Graviton2处理器。Ampere将于今年年底提供其128核N1处理器(Altra Max)的样品。Fugaku利用定制的Arm平台(由Fujitsu和Riken开发的A64FX)来设置多个基准记录,并协助对抗COVID-19。Marvell的Arm实施ThunderX取得了一些成功(在2018年宣布了首个Petascale Arm系统,并赢得了其他几项重大设计大奖),但最近宣布了向半定制的转变。
强劲的发展势头引起了芯片暨数据中心公司Nvidia的关注。在加深了对Arm平台的支持之后,Nvidia决定继续自己的公司。在获得监管部门批准之前,英伟达将以400亿美元的价格收购母公司软银的IP芯片部门。