近期学习HIVE,通过动手操作,收获不小,现将遇到的6个问题及解决方法分享给大家,希望对大家学习HIVE有帮助,如下:
1.hive作业提交问题hive如何放到一个脚本中并行执行
有3个sql文件,a,b,c,需要并行执行,现在的做法是开3个hive的cli,分别运行a,b,c,比如有个个test.sh脚本内容如下
hive -f a.sql
hive -f b.sql
hive -f c.sql
然后去运行,结果成了跑完abc三个顺序运。
解决的办法:
hive -f a.sql
hive -f b.sql &
hive -f c.sql &
2.Hive查询表 数据全是NULL
sample.txt格式如下:
1 duck
2 chiken
3 pig
4 elephant
5 fish
6 monkey
7 donkey
8 duck
9 chiken
10 pig
HQL语句如下:create table animal(id INT,name STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY 't' LINES TERMINATED BY 'n' STORED AS TEXTFILE;
LOAD DATA LOCAL INPATH '/tmp/sanple.txt' overwrite into table animal;
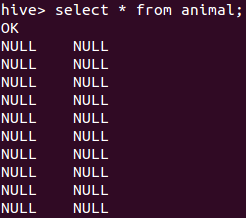
解决办法:
LOAD DATA LOCAL INPATH '/tmp/sanple.txt' overwrite into table animal FIELDS TERMINATED BY 't';
解释:
数据分隔符的问题,定义表的时候需要定义数据分隔符,
FIELDS TERMINATED BY 't'
这个字段就说明了数据分隔符是tab。
3.hive读取二进制文件
建了一个有45个double类型组成的表:
create table dht_tab(name1 DOUBLE ,name2 DOUBLE, ... ,name45 DOUBLE);
本地磁盘上有个名为“dhtnew.dh”的一个数据,可看为45*n个DOUBLE型的2进制字节的顺序文件组成。
将其导入的语句是:
load data local inpath 'dhtnew.dh' overwrite into table dht_tab;
但是后来查看的时候表是空的,貌似全部违反了schema。
解决办法:
两种解决方案
1、修改C Code,用文本输出,每个DOUBLE之间一个分隔符分割数据列
2、把原数据全部导入HDFS,然后写一个MAPREDUCE,重整这些数据到文本
4.hive 分隔符
- > CREATE TABLE IF NOT EXISTS testdb2.employees (
- > name STRING COMMENT 'Employee name',
- > salary FLOAT COMMENT 'Employee salary',
- > subordinates ARRAY<STRING> COMMENT 'Names of subordinates',
- > deductions MAP<STRING, FLOAT>
- > COMMENT 'Keys are deductions names, values are percentages',
- > address STRUCT<street:STRING, city:STRING, state:STRING, zip:INT>
- > COMMENT 'Home address')
- > COMMENT 'Description of the table'
- > TBLPROPERTIES ('creator'='me', 'created_at'='2012-01-02 10:00:00');
- OK
- Time taken: 0.132 seconds
- > load data local inpath '/tmp/zong'
- > overwrite into table employees;
- Copying data from file:/tmp/zong
- Copying file: file:/tmp/zong/hive_random_name.txt
- Loading data to table testdb2.employees
- Deleted hdfs://tkpcjk01-10:8020/user/hive/warehouse/testdb2.db/employees
- OK
- Time taken: 1.247 seconds
- 目录/tmp/zong 下只有一个文件,里面有三行文本:
- [root@tkpcjk01-11 zong]# cat /tmp/zong/hive_random_name.txt
- Mary Smith^A80000.0^ABill King^AFederal Taxes^C.2^BState Taxes^C.05^BInsurance^C.1^A100 Ontario St.^BChicago^BIL^B60601
- Todd Jones^A70000.0^AFederal Taxes^C.15^BState Taxes^C.03^BInsurance^C.1^A200 Chicago Ave.^BOak Park^BIL^B60700
- Bill King^A60000.0^AFederal Taxes^C.15^BState Taxes^C.03^BInsurance^C.1^A300 Obscure Dr.^BObscuria^BIL^B60100
- 加载到employee表中后,怎么三行记录都跑到 表中的 name 列了
- > select * from employees;
- OK
- name salary subordinates deductions address
- Mary Smith^A80000.0^ABill King^AFederal Taxes^C.2^BState Taxes^C.05^BInsurance^C.1^A100 Ontario St.^BChicago^BIL^B60601 NULL null null null
- Todd Jones^A70000.0^AFederal Taxes^C.15^BState Taxes^C.03^BInsurance^C.1^A200 Chicago Ave.^BOak Park^BIL^B60700 NULL null null null
- Bill King^A60000.0^AFederal Taxes^C.15^BState Taxes^C.03^BInsurance^C.1^A300 Obscure Dr.^BObscuria^BIL^B60100 NULL null null null
- Time taken: 0.337 seconds
解决办法:
1.确定一下ctrl+A没问题
2.row format delimited fields terminated by 't'将分隔符修改成 tab
3.尝试hive默认的分隔符是‘�01’
5.hive 如何安全退出
解决办法:
1.hive> exit;
2.hive>quit;
3.更安全的办法:
exit;
hadoop job -kill jobid
---------------------------------------------------------------------------------------------------------------------------------------------------
6.HIVE和HBASE数据对接
在Hbase中有一张表TB_1
FNAME:"C1
随后,在Hive中创建了一张映射表TB_1
当HBASE的数据发生改变时,Hive可以读取到往HIVE里插入新数据后,HBASE里能看不到
解决办法:
HIVE的映射表无法更新HBASE中已存在的数据表