虚拟化技术在数据中心是个时髦词儿,有横向虚拟化、纵向虚拟化、一虚多虚拟化、NVO3虚拟化等等。今天重点跟大家聊聊横向虚拟化,以华为CloudEngine 12800系列为例,让朋友们了解一下此技术的由来和发展史,深入浅出地介绍下各种横向虚拟化技术的特点、以及各种场景下的选择策略。
横向虚拟化集群由来
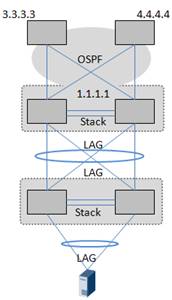
在数据中心网络发展初期,没有专门的数据中心交换机,那咋办?先拿园区交换机顶着,使用最传统的VRRP+STP,凑合着用吧,就是下面这张经典的园区网络。

这个网络模型,透着浓浓的经典、可靠的园区味道。可时间久了,问题就来了:
l 流量越来越大,STP阻断导致链路利用率低;
l 非最短路径转发,树根存在带宽瓶颈,转发时延大;
l VRRP单活网关,备节点设备闲置;
l STP网络规模受限,收敛性能较差;
l 管理节点多,逻辑拓扑复杂,维护麻烦。
这些问题带来横向虚拟化的诉求,框式交换机集群率先登场。
堆叠
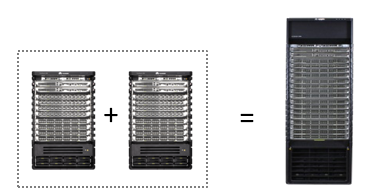
典型的框式交换机堆叠,有CISCO的VSS(Virtual Switch System)、华为的CSS(Cluster Switch System)、H3C的IRF(Intelligent Resilient Framework)。VSS、CSS、IRF在本质上都是堆叠,只是穿了不同的马甲而已,当然各厂家也发展出一些差异,这是后话。
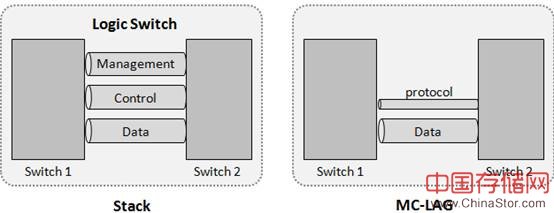
堆叠技术,本质上就是合并,管理平面、控制平面、转发平面的全面合并。堆叠系统的主控板,管理两台物理设备的所有线卡和网板,变成一个逻辑的大交换机。
但需要注意,堆叠目的不仅仅是为了变大,从网络角度看一下逻辑拓扑,一下变得“高富帅”!

“高富帅”的主要表现:
l 几乎两倍交换能力的超级节点;
l 二三层转发流量完全负载分担,充分利用所有链路;
l 逻辑单节点,业务支持全面,网络方案设计简单;
l 通过部署跨框link-agg,支持物理节点的故障保护;
l 网元二合一,有利于网络管理和维护。
还有零零碎碎的好处也不少:
l 最短路径转发,时延低;
l 相对传统STP,可以组建更大的二层网络;
l link-agg的收敛性能,网络故障收敛块。
在堆叠系统中,堆叠链路的带宽相对于业务端口,带宽总是不够的。这就要求转发的业务流量尽量避免经过堆叠链路,这就是所谓的流量本地优先转发。

如上图所示,华为数据中心交换机堆叠系统,对三层ECMP、链路捆绑支持本地优先。本地优先转发节省了堆叠链路带宽,同时也达到减少转发时延的目的。
除了上述通用的堆叠技术,华为CloudEngine 12800系列数据中心高端交换机,还针对堆叠的可靠性,做了重大的体质性的优化。
堆叠的优化
可靠性优化(转控分离的堆叠)
转控分离的堆叠,也称为带外堆叠,这个优化主要目的是高可靠性。
业界大部分框式交换机的堆叠,堆叠成员间的控制通道和转发通道都使用一个通道。华为的CloudEngine 12800系列数据中心交换机独创性的开发了转控分离的堆叠系统。这里的“转”指的是业务数据转发通道;“控”指的是控制消息(也称为“信令”)通道。
传统的框式堆叠系统,业务数据通道和控制消息通道都使用相同的物理通道,即堆叠链路。如下图所示:
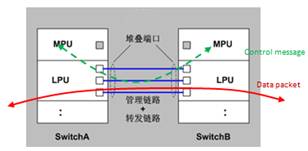
这种堆叠系统,控制消息和数据混合在一起运行,如果堆叠通道的数据通信量大,则可能导致控制消息受到冲击而丢失,进而影响控制面的可靠性。严格来说,这种设计没有满足“数据、控制、管理平面分离”的设计要求。此外,堆叠系统的建立,依赖线卡的启动,导致软件复杂度的提高,以及影响堆叠的启动速度。
转控分离的堆叠系统,采用如下所示架构:
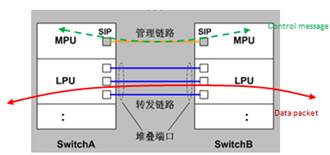
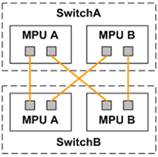
该硬件堆叠架构带来一系列可靠性的提升:
l 控制消息通道和业务数据通道物理隔离,保证业务数据不影响控制消息;
l 三重的双主故障防护,包括堆叠管理链路(4路)、堆叠转发链路(至少2路)、业务端口/管理端口DAD;
l 堆叠系统建立,不再依赖线卡的启动,无软件时序依赖,简化软件实现,而简单意味着可靠;
l 堆叠系统建立,不再等待线卡/网板的启动,缩短堆叠系统建立时间;
l 控制消息通道路径短,故障点少,时延低。
堆叠改良的局限性
堆叠系统带来了前述系列的好处,但慢慢的,令人不爽的问题也逐渐暴露出来,这是由堆叠原理本质决定的。


如上图所示,两台交换机通过管理平面、控制平面、数据平面的紧耦合,形成逻辑上的一台交换机。这导致了如下三个风险或者问题。
l 整系统级可靠性风险
对于普通的故障,堆叠系统可通过链路切换、主备板切换、 框切换等完成故障保护。但是由于整个系统的两台物理switch在软件(管理平面、控制平面)是紧耦合的,这就增大软件故障从一台switch扩散到另一台Switch的可能性。一旦出现这种类型的故障,将导致整个堆叠系统的故障,影响堆叠系统接入的所有业务。
l 版本升级的业务中断时间长
由于堆叠本身承担了业务保护功能,因此当堆叠系统升级时,不能像VRRP的成员节点升级时由另外一个节点进行流量保护,中断时间比较长。
对此,各厂商开发出了两框RoundRobin和ISSU的升级方式,这些升级方式缩短了升级时的业务中断时间,但并不解决下面所说的升级风险,甚至因为技术复杂度、软件工程复杂度的提升,放大了升级风险。
l 整系统升级风险
设备软件版本升级,即使采用最传统、简单的升级方式,也是一个带风险的网络操作。设备升级失败将导致该设备所带业务失效,这种情况下,要采用包括回退在内的一切手段尽快恢复业务。
堆叠系统由于成员交换机间的紧耦合,只能是两台设备一起升级,升级失败将导致堆叠系统下所有业务网络中断。而堆叠系统,在接入层往往承担服务器双归保护接入的角色、或者在汇聚承担高可靠性网关的角色,这意味着升级失败很可能导致整个业务的瘫痪。
Link-agg虚拟化(M-LAG)
横向虚拟化,从需求角度是为了满足接入层、汇聚层的二层跨设备冗余、汇聚层L3网关的跨设备冗余。那是否还有其他技术,支持横向虚拟化,又没有堆叠的哪些问题?
答案当然是有,华为CloudEngine系列数据中心交换机的M-LAG(Multichassis Link Aggregation Group)就支持这样的虚拟化技术。该技术只在两台设备的link-agg层面实现二层虚拟化,两台成员设备的管理和控制平面是独立的。
注:维基百科称此技术为MC-LAG(Multi-Chassis Link Aggregation Group),CISCO称之为vPC(Virtual Port-Channel)。下文都采用维基百科的术语,即简写为MC-LAG。

MC-LAG,支持的跨设备链路捆绑组网,支持Dual-Active的L3GW。在接入侧,从对端设备视角、服务器视角看,MC-LAG与堆叠类似。
但是,从三层网络角度看,MC-LAG的两个成员节点拥有自己独立的IP地址,两个节点有自己独立的管理和控制平面。从架构角度看,MC-LAG的两个成员设备仅存在数据面的耦合,以及协议面的轻量级耦合:
MC-LAG的架构,决定了此技术方案不存在堆叠难解决的三个问题:
|
问题/风险 |
MC-LAG解决的原因 |
|
整系统级可靠性风险 |
两个成员节点,在软件上只有协议级的弱耦合,因此故障传递的可能性大大降低 |
|
版本升级的业务中断时间长 |
两个成员节点,在软件上只有协议级的弱耦合,支持一个成员节点单独升级。升级期间,另外一台成员负责转发,业务中断时间只有秒级 |
|
整系统升级风险 |
两个成员节点,在软件上只有协议级的弱耦合,支持一个成员节点单独升级。即使升级失败,还有一台成员正常工作。 |
那么,说了MC-LAG的这么多好处,是不是就没有缺点了?当然不是,寸有所长,尺有所短。最后一节比较堆叠与MC-LAG的优缺点,以及场景选择建议。
堆叠和MC-LAG的对比和选择建议
|
堆叠 |
MC-LAG |
|
|
理论可靠性 |
较低 管理面、控制面、数据面紧耦合,软件故障可能跨框传递,因此理论可靠性相对较低 |
高 在软件上只有协议级的弱耦合,因此故障传递的可能性大大降低,理论可靠性高 |
|
升级风险 |
风险高 升级失败将导致堆叠系统下所有业务网络中断,升级风险高 |
风险低 支持一个成员节点单独升级,即使升级失败,还有一台成员正常工作,升级风险低 |
|
升级中断时间 |
中断时间长 普通升级十分钟级 两框RoundRobin为十秒级~分钟级,和业务相关 ISSU的升级,秒级或者无中断 |
中断时间短 普通升级秒级 ISSU无中断 |
|
网络方案设计 |
简单 按单节点设计 |
相对复杂 在三层网络侧需按双节点设计 |
|
特性支持度 |
全面 几乎支持所有特性 |
相对弱 不支持所有特性,但支持数据中心常用的基础二三层、TRILL、VXLAN等常用协议 |
|
配置&维护方便性 |
简单 只需维护单节点 |
相对复杂 需要维护双节点 |
根据上面的对比表格,堆叠和MC-LAG各有优缺点。总的来说,对于网络设计/维护人员,堆叠胜在管理维护简单,MC-LAG胜在可靠性和低升级风险。
在数据中心网络方案设计时,需要权衡考虑,有如下策略可以选择:
l 策略一:汇聚层优先考虑可靠性、升级方便性,选择M-LAG;接入层因为设备量大,优先考虑业务部署和维护方便性,选择堆叠。
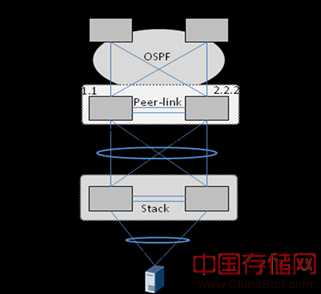
l 策略二:优先考虑可靠性、升级低风险,汇聚和接入都使用M-LAG。

l 策略三:优先考虑业务部署和维护方便性,汇聚和接入都使用堆叠。