
随着数据的重要性深入人心,数据备份成为企业运营发展的“必需品”,大多数企业都会通过定期备份来预防意外停机、数据受损等“天灾人祸”。数据存储的规模每12个月到18个月就会翻番,因此,帮助企业增加可用数据空间,节省在数据空间的成本投入是非常值得关注的事。
例如,一家企业拥有400名员工,他们使用台式机和笔记本电脑。一台普通的笔记本电脑可以在硬盘上保存50到数百GB的数据。所有PC包含20到150TB的数据。压缩率为2:1时,备份管理员需要为每个完整备份提供10到75TB的空间,并且还需要额外的空间用于增量备份和差异备份。最终,该企业需要为PC数据备份准备多达1PB的存储空间。
假设该企业为PC备份投资了昂贵的存储设备。下一个更大的挑战是将PC备份到此存储中。一个100 Mbit(兆位)的网络每秒只能传输10 MB的数据。以这种速度,完整备份将需要两到三周的时间才能传输10到75TB的数据。
况且,每台电脑都拥有相同的Windows操作系统、相同的应用程序以及相同数据的多个副本。研究表明,如果备份解决方案仅传输和存储唯一数据,则企业最多能够将其存储容量和网络需求降低50倍。如果同一数据多次存储和传输到同一存储设备,就是对时间和资源的极大浪费,而人工去查验这些重复数据将耗费大量的时间和人力。基于这种需求,数据备份保护过程中的重复数据删除技术应运而生。
什么是备份重复数据删除?
备份重复数据删除是通过检测数据重复并将同一数据仅存储一次来最大程度地减少存储空间的技术。重复数据删除还可以缩减历史数据的大小,从而节省大量存储成本,并防止未来从多个来源复制类似数据。
重复数据删除可优化冗余,而不会损坏数据真实性或完整性。启用重复数据删除后,您的备份解决方案将对数据进行分段,对照之前已写入的数据矩阵进行检查。将备份进行重复数据删除并将其保存到托管存储中。启用重复数据删除的存储位置被称为重复数据删除存储。
除此之外,重复数据删除可以在文件级,子文件级(文件片段)或块级运行,通常可以与备份解决方案支持的所有操作系统一起使用。
备份重复数据删除的工作原理
重复数据删除将备份数据集拆分为多个数据块。每个数据块的唯一性通过一个特殊的数据库进行检测,该数据库跟踪所有存储的数据块的校验和。唯一数据块被发送到存储,并且重复项被跳过。
例如,如果将10个虚拟机备份到重复数据删除的存储中,并且在其中五个中找到相同的数据块,则仅发送和存储该数据块的一个副本。
这种跳过重复数据块的算法节省了存储空间,并使网络流量最小化。
源端重删
在对重删存储执行备份时,备份解决方案将计算每个数据块的指纹或校验和。此指纹或校验和通常称为哈希值。
您的备份解决方案可能支持固定大小或可变大小的数据块。事实证明,固定大小的数据块重复数据删除效果并不佳,在较小的数据块上会消耗大量内存和CPU资源;在较大的数据块上提供了更低的重删率。
最先进的现代备份解决方案提供了可变大小的数据块重删功能,可以调整块大小以实现最大化重删率,同时减少内存和CPU的使用率。
在将数据块发送到存储之前,备份解决方案将查询存储系统以确定该数据块的哈希值是否已经存储在其中。如果已存储,则解决方案仅发送哈希值;反之,则发送数据块本身。
对于加密文件或非标准大小的磁盘块数据无法进行重复数据删除。在这些情况下,解决方案始终将此数据传输到存储中,而无需计算哈希值。
目标端重删
完成对重复删除存储的备份后,存储系统将执行存储端重复数据删除。通常,此过程的工作方式如下:
- 数据块从备份文件移动到存储中的一个特殊文件中(重删数据存储)。重复的数据块仅存储一次。
- 哈希值到数据块的链接已保存到重删数据库中,因此可以轻松地重组数据。
所以,数据存储区包含许多唯一的数据块。每个数据块都有一个或多个备份参考。引用记录在重复数据删除数据库中。
下图说明了目标端重删的结果:
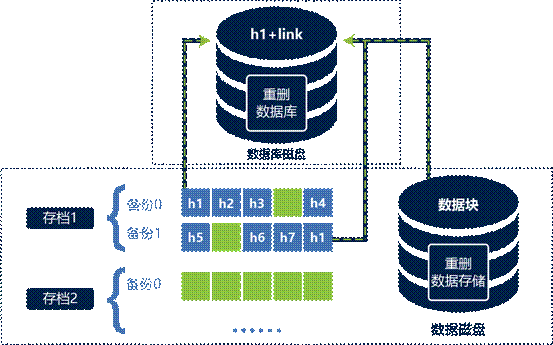
该图显示了两个备份存档。每个都有单独的一组备份。在档案1中,h1到h7(由蓝色块指定)包含存储在备份文件中的哈希值。绿色块是无法重复数据删除的数据块。存档2仅包含数据(绿色)块,并且已加密。重复数据删除数据库:包含可以进行重删数据块的哈希值,重复数据删除数据存储:包含来自存档1和存档2的数据块。
恢复
在恢复期间,备份解决方案代理会从存储中请求数据。存储系统从存储中读取备份数据,如果在重删数据存储中引用了块,则存储系统将从中读取数据。对于代理,恢复过程是透明的,并且与重复数据删除无关。
删除孤立数据块
从存储中删除一个或多个备份后(手动或通过保留规则),数据存储区可能包含数据块,任何备份都不再引用这些数据块。这些孤立数据块将由存储系统运行的特殊计划任务删除。
其工作原理是:首先,存储系统会扫描存储中的所有备份,并将所有引用的数据块标记为已使用(在重复数据删除数据库中将适当的哈希标记为已使用)。其次,存储系统删除所有未使用的数据块。
此过程可能需要其他系统资源。这就是为什么此任务通常仅在存储中积累了足够数量的数据时才能运行的原因。
压缩和加密
备份解决方案代理通常会先压缩备份的数据,然后再将其发送到服务器。在压缩之前计算每个数据块的哈希值。这意味着,如果两个相等的数据块即使以不同的压缩级别进行压缩,则它们仍被视为重复项。出于安全原因,不会对源端加密的备份进行重复数据删除。
为了同时利用加密和重复数据删除功能,您的备份解决方案应支持对托管存储本身进行加密。在这种情况下,恢复期间,数据将由存储系统使用存储特定的加密密钥透明地解密。如果存储介质被盗或被未经授权的人员访问,则存储在不访问存储系统的情况下是无法被解密的。
什么时候应该使用重删?
当重删率最低时,重复数据删除的影响最大。这是重复数据删除率计算的公式:
重删率=唯一数据百分比+(1-唯一数据百分比)/机器数量
这意味着:
1. 重删在每台机器上都有大量重复数据的环境中最有效。
2. 重删在需要备份许多类似机器/虚拟机/应用程序的环境中最有效。
此外,重删还可以在其他情况下提供帮助,例如,当尝试优化广域网(WAN)时。
让我们看看一些典型的用例。
用例1:具有类似机器的大环境
环境
需要备份一百台相似的工作站。最初使用磁盘镜像系统部署解决方案来部署工作站。
重删效果
工作站是从一个系统镜像部署的,因此在所有计算机上运行的操作系统和通用应用程序是相同的。结果,有很多重复项。重删率更高,因为工作站数量很多。
结论
在这种情况下,重复数据删除非常有效,因为可以最大程度地减少存储容量并节省存储成本。
用例2:WAN优化
环境
办公室中的40台相似工作站需要备份到远程位置。
重删效果
不确定工作站是否从一个系统镜像部署。但是,相似类型的操作系统通常具有许多相似文件。假设每台PC上50%的数据都是唯一的,对于重复数据删除来说效果还是相当不错的:
重复数据删除率= 50%+(100%– 50%)/ 40 = 51.25%
大约可节省48.75%(100%– 51.25%)的存储和网络流量,这意味着重复数据删除将这些需求几乎减少了一半。由于系统已备份到远程位置,因此WAN连接可能相对较慢。将流量减半提供了很大的优势。
结论
对于这种情况,重复数据删除是一种有效的解决方案,因为它可以优化WAN网络。
用例3:关键业务应用服务器
环境
需要备份五台具有不同应用程序的服务器。数据总量为20TB。
重删效果
应用程序服务器托管大量数据和不同的应用程序。这意味着几乎没有重复项。此外,要备份和处理的数据总量非常大。在这种情况下,存储系统对大量数据建立索引,但是由于没有重复项,因此几乎没有重删效果。在最坏的情况下,单个存储系统可能无法在一天内处理所有备份。
结论
重复数据删除在这种情况下无效。备份到简单的大容量网络附加存储(NAS)是更好的解决方案。
重复数据删除总结
备份重复数据删除技术通过删除备份和传输数据时的重复数据块,从而降低存储成本和网络带宽占用。
重复删除技术可以帮助实现:
- 通过仅存储唯一数据来减少存储空间使用。
- 无需投资于重复数据删除专用硬件。
- 减少网络负载,因为传输的数据更少,从而为您的生产任务留出更多带宽。
需要注意的是,经过重复数据删除的存储可能需要更多的计算资源,例如内存和/或CPU。在某些情况中,传统的非重复数据删除存储可能比重复数据删除更具成本效益。在实施重复数据删除之前,应该始终分析用户的需求和基础架构。